bytedance
78 articles in this category (Page 7 of 9)

ReVidgen: The Future of Video Generation for the Physical World
ReVidgen: The Future of Video Generation for the Physical World
Read more →
Mastering High-Resolution Video Matting with Robust Temporal Guidance
Mastering High-Resolution Video Matting with Robust Temporal Guidance
Read more →

SAMTok: Converting Complex Image Masks into Two Simple Words for MLLMs
SAMTok: Converting Complex Image Masks into Two Simple Words for MLLMs
Read more →

SeedFold: Scaling Biomolecular Structure Prediction
SeedFold: Scaling Biomolecular Structure Prediction
Read more →

Show-o: The All-in-One Transformer Revolutionizing Multimodal AI Generation and Understanding
Show-o: The All-in-One Transformer Revolutionizing Multimodal AI Generation and Understanding
Read more →
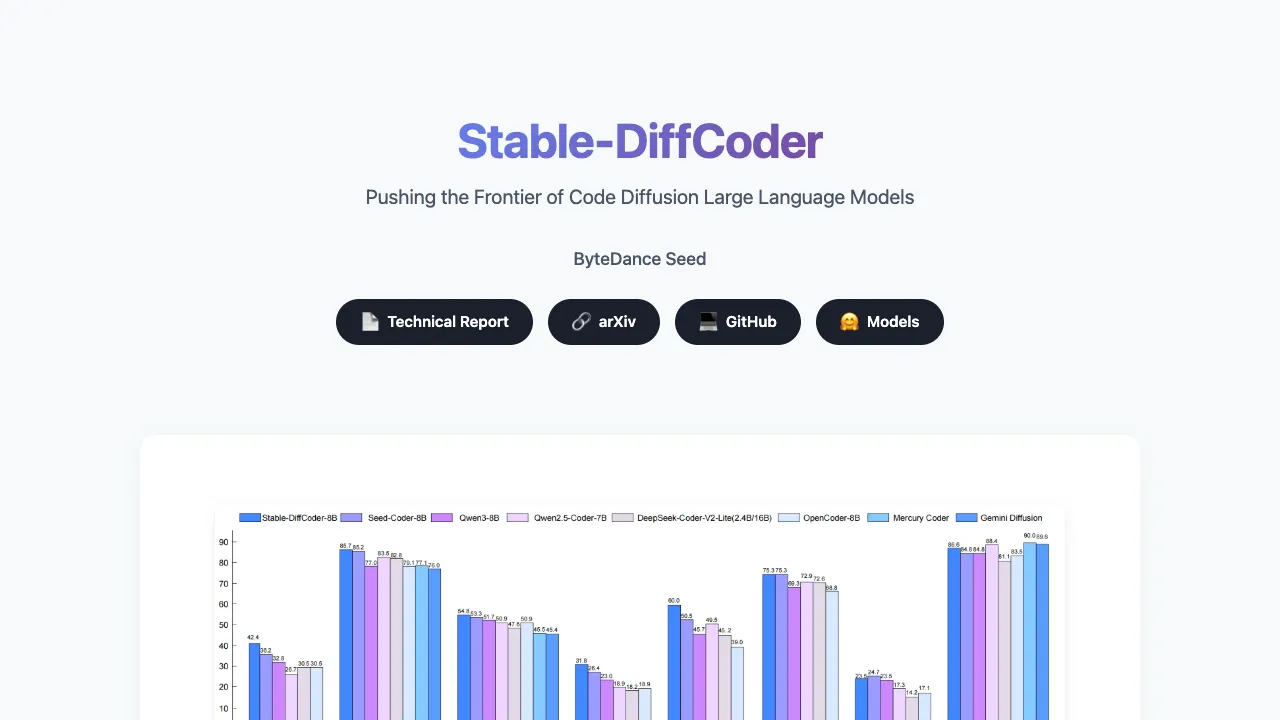
Stable-DiffCoder: The New Frontier of AI-Powered Code Generation
Stable-DiffCoder: The New Frontier of AI-Powered Code Generation
Read more →

StereoWorld: Transforming 2D Videos into Immersive 3D Reality with Geometry-Aware Tech
StereoWorld: Transforming 2D Videos into Immersive 3D Reality with Geometry-Aware Tech
Read more →
StoryMem: Multi-shot Long Video Storytelling with Memory
StoryMem: Multi-shot Long Video Storytelling with Memory
Read more →

From Text to Sound: How Make-An-Audio Revolutionizes Audio Generation with Diffusion Models
From Text to Sound: How Make-An-Audio Revolutionizes Audio Generation with Diffusion Models
Read more →