SAMTok: Converting Complex Image Masks into Two Simple Words for MLLMs

What is SAMTok: Converting Complex Image Masks into Two Simple Words for MLLMs
SAMTok turns complex image areas (called masks) into just two special words that a language model can read and write. This makes pixel-level tasks, like picking out a person or an object in a photo, as easy as reading and typing.

It also works the other way around. From those two words, SAMTok can rebuild the exact mask for the region in the image.
SAMTok: Converting Complex Image Masks into Two Simple Words for MLLMs Overview
SAMTok is a small but smart “mask tokenizer.” It teaches a multi-modal language model (MLLM) to understand and create pixel masks without changing the model’s parts. The model just learns to predict the next token, like normal text training.

Here is a quick overview you can skim in seconds:
| Item | Summary |
|---|---|
| Project Name | SAMTok: Converting Complex Image Masks into Two Simple Words for MLLMs |
| Type | Discrete mask tokenizer for MLLMs |
| Purpose | Convert image masks into short text tokens and back to masks |
| What It Solves | Lets MLLMs point to regions in images using simple words, then rebuild those regions as masks |
| Works With | Any base MLLM (e.g., QwenVL family, others) via next-token training |
| Key Parts | Encoder, two-stage vector quantizer, decoder (built on SAM) |
| Tasks | Mask understanding (refer to regions) and mask generation (create masks from text) |
| Training Style | Supervised fine-tuning and reinforcement learning; no special loss or model changes needed |
| Official Page | Project website |
For more plain-English AI explainers and roundups, visit our main site.
SAMTok: Converting Complex Image Masks into Two Simple Words for MLLMs Key Features
- Turns any 2D mask into two special tokens, and can rebuild the mask from those tokens.
- Teaches an MLLM pixel-level skills using simple next-token training, so no model parts need to change.
- Uses a two-stage quantizer so the tokens are stable and accurate for many shapes.
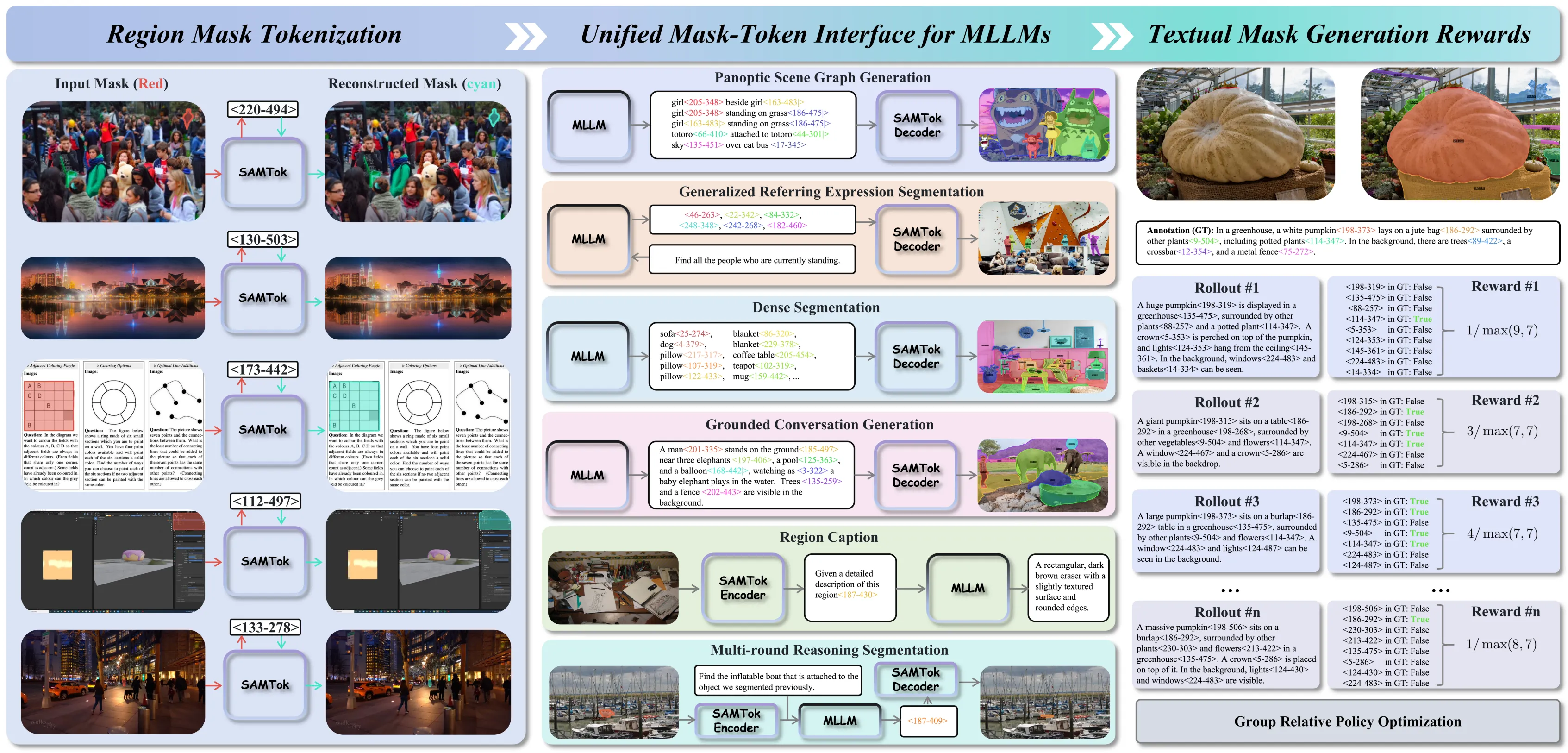
- Works for two sides of the task: “understand a region” from tokens or “create a region” from an instruction.
- Built on the SAM family for strong mask quality while keeping the interface text-only for the language model.
SAMTok: Converting Complex Image Masks into Two Simple Words for MLLMs Use Cases
-
Region Q&A: Ask about a specific area, like “What is the person holding?” and point to that region with mask words.
-
Creative editing: Select parts of a photo (sky, shirt, car) using words, then edit just that part.
-
Product or scene search: Refer to objects by area in e‑commerce photos or street scenes.
-
Robotics guidance: Mark pick-up zones or no-touch areas using tokens, then rebuild to real masks for actions.
-
Medical or industry: Mark tissues, parts, or defects with reliable region tokens for review or training.
For a quick look at how firms push region-level AI, see our short take on ByteDance research notes.
How It Works
SAMTok has three parts: an encoder, a vector quantizer with a codebook, and a decoder. The encoder and decoder are both built from SAM, which has an image backbone, a prompt encoder, and a mask decoder.
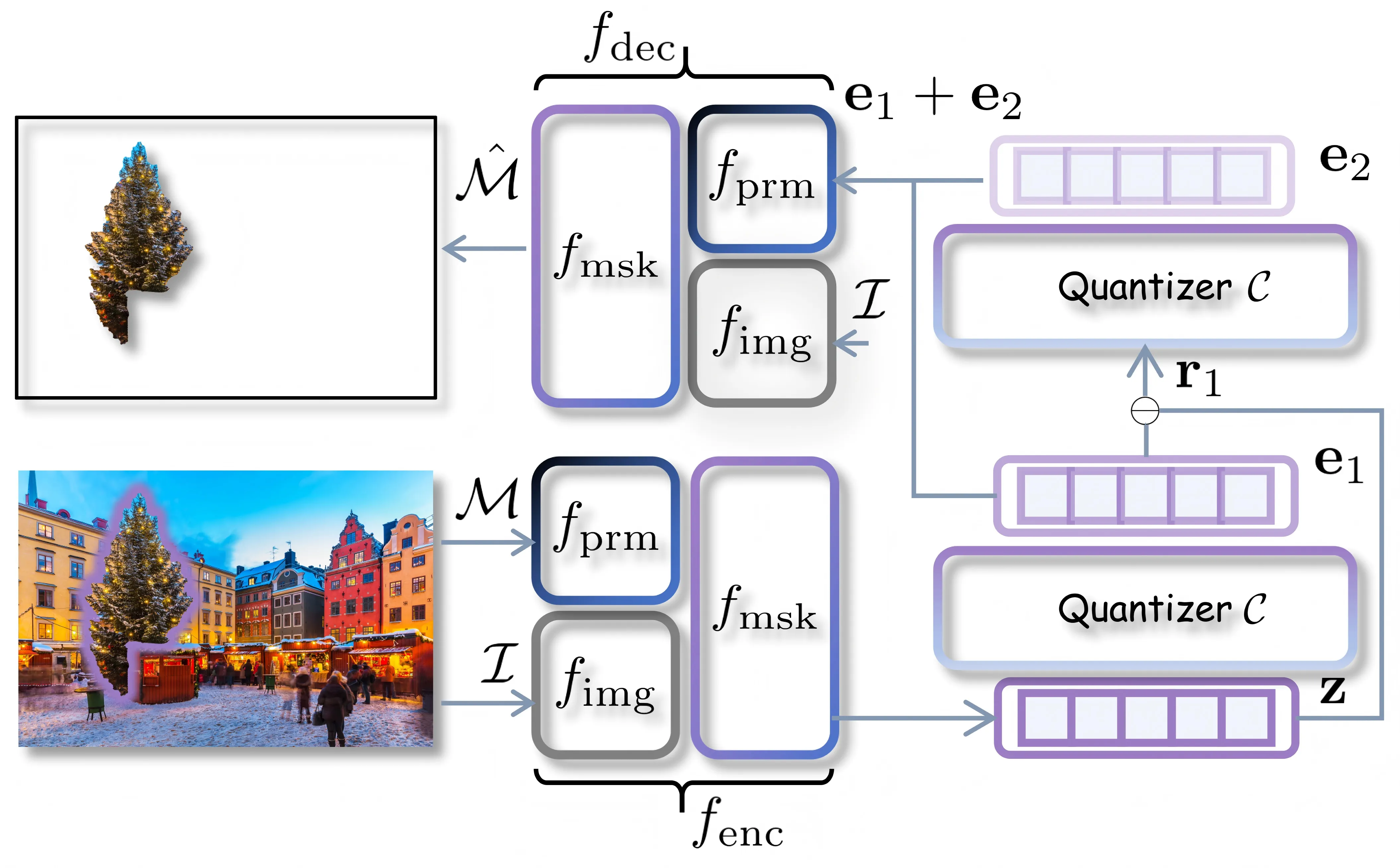
- Given an image and a region mask, the encoder turns the 2D mask into an embedding, then runs a two-step quantization to get two discrete codes. 2) These codes become two “mask words” that the MLLM can read or write in a normal text prompt. 3) For output, SAMTok maps the words back to codes and rebuilds the 2D mask with the decoder.
The Technology Behind It
- Mask understanding: First tokenize region masks into codes, format them as mask words, and insert them in the MLLM prompt. The MLLM can then reason about that exact region.
- Mask generation: The MLLM writes mask words from an instruction. SAMTok maps the words to codes and reconstructs the final mask.
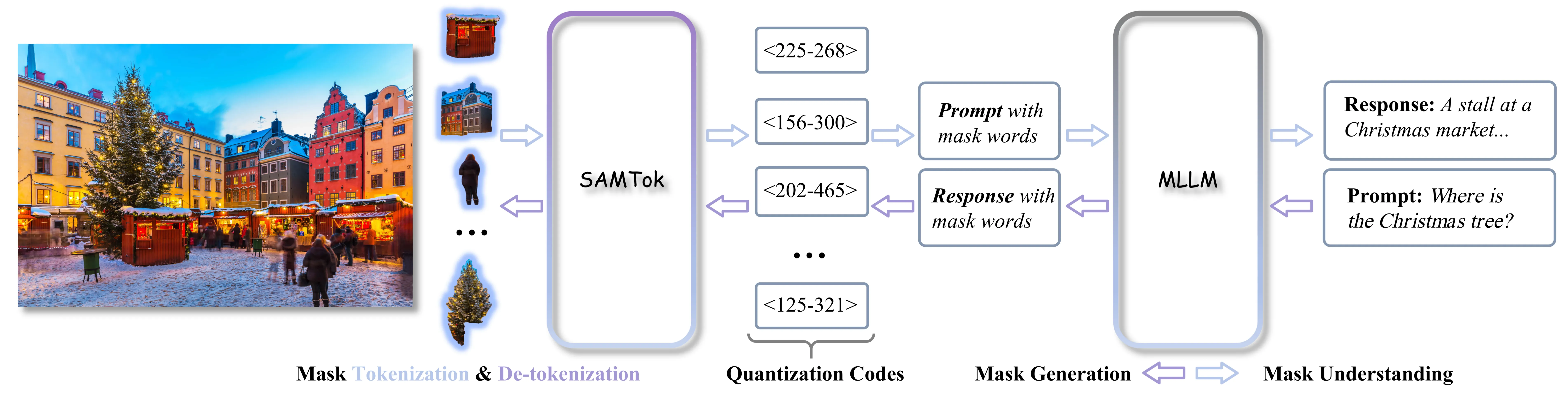
- Training is simple: supervised fine-tuning and reinforcement learning on text tokens. No new loss terms and no changes to the model parts.
Performance & Showcases
Here are sample outcomes that show stable mask quality and region-aware reasoning. You can see how the same two-word format can cover many shapes and sizes.

In more trials, SAMTok keeps masks faithful to the target region even when the region is small or thin. This is key for precise pointing with language.

On instruction tasks, the model can read or write mask words to isolate a subject, like “the red bag” or “the main character.” The rebuilt masks stick close to the text intent.

When training with both supervised signals and simple policy steps, the two-token format stays easy to learn. It fits well with normal language training loops.

Installation & Setup (Hands-on via Sa2VA, a Related Open-Source Stack)
The project page shows how SAMTok works. If you want a working system today for image/video region tasks that follows the same mask‑plus‑language idea, you can try Sa2VA (SAM2 + LLaVA). Below are the exact steps from the Sa2VA GitHub to set up a local demo, training, and evaluation.
Gradio chat demo:
PYTHONPATH=. python projects/sa2va/gradio/app.py ByteDance/Sa2VA-4B
Environment with uv:
- uv sync --extra=legacy for InternVL2.5 or earlier models (legacy Transformers).
- uv sync --extra=latest for newer models (latest Transformers).
Quick Start (script option):
python demo/demo.py PATH_TO_FOLDER --model_path ByteDance/Sa2VA-8B --work-dir OUTPUT_DIR --text "<image>Please describe the video content."
Install uv (recommended path):
curl -LsSf https://astral.sh/uv/install.sh | sh
Create venv and sync deps:
uv sync --extra=latest # or uv sync --extra=legacy for Sa2VA based on InternVL2/2.5
source .venv/bin/activate
Place pretrained models like this:
./ # project root
pretrained/
├── sam2_hiera_large.pt
├── InternVL2_5-1B
├── InternVL2_5-4B
Unzip video data:
unzip video_datas_mevis.zip
Your data tree should look like this:
data/
├── video_datas
| ├── revos
| ├── mevis
| └── davis17
| └── chat_univi
| └── sam_v_full # [!important] please download this from sam-2 directly.
| └── Ref-SAV.json
├── ref_seg
| ├── refclef
| ├── refcoco
| ├── refcoco+
| ├── refcocog
| ├──
├── glamm_data
| ├── images
| ├── annotations
├── osprey-724k
| ├── Osprey-724K
| ├── coco
├── llava_data
| ├── llava_images
| ├── LLaVA-Instruct-150K
| ├── LLaVA-Pretrain
Train on 8 GPUs:
bash tools/dist.sh train projects/sa2va/configs/sa2va_in30_8b.py 8
Convert to Hugging Face format:
python tools/convert_to_hf.py projects/sa2va/configs/sa2va_in30_8b.py --pth-model PATH_TO_PTH_MODEL --save-path PATH_TO_SAVE_FOLDER
Evaluate on all video segmentation sets:
python projects/sa2va/evaluation/run_all_evals.py /path/to/SA2VA/model --gpus 8
Tip: In Sa2VA, “sam_v_full” must be fetched from Meta’s SA‑V dataset under their license.
Read More: About our publication and team
Step-by-Step: Try the Local Chat
- Install uv, create the venv, and sync with the “latest” extra. Then activate the venv.
- Put the pretrained files in the “pretrained” folder as shown.
- Launch the Gradio app with the 4B model and start chatting about your images or videos.
If you prefer scripts, point to a folder of video frames. Then run the demo command to get both text and segmentation outputs saved to your output directory.
Tips for Better Results
- Keep your instruction short and clear, like “Segment the person in yellow.”
- If you have many frames, place them in order so the script reads them correctly.
- Start with the 4B model for fast tests, then try larger models if you need higher quality.
FAQs
What does “two words” mean in SAMTok?
These are special tokens made by the quantizer. Together, they point to one region mask in the image.
Can I teach my own MLLM to use SAMTok?
Yes. The model learns to read and write those two tokens during normal next-token training. No changes to the model parts are needed.
Does this help with both finding and making masks?
Yes. For finding, the prompt includes mask words that refer to regions. For making, the model writes mask words from a text instruction, then SAMTok rebuilds the mask.
How is this different from prompts like “click points”?
Here, the MLLM can speak “in tokens” about regions. It keeps the whole loop in text form, which is simple for training and control.
Image source: SAMTok: Converting Complex Image Masks into Two Simple Words for MLLMs