InfiniteYou AI by ByteDance
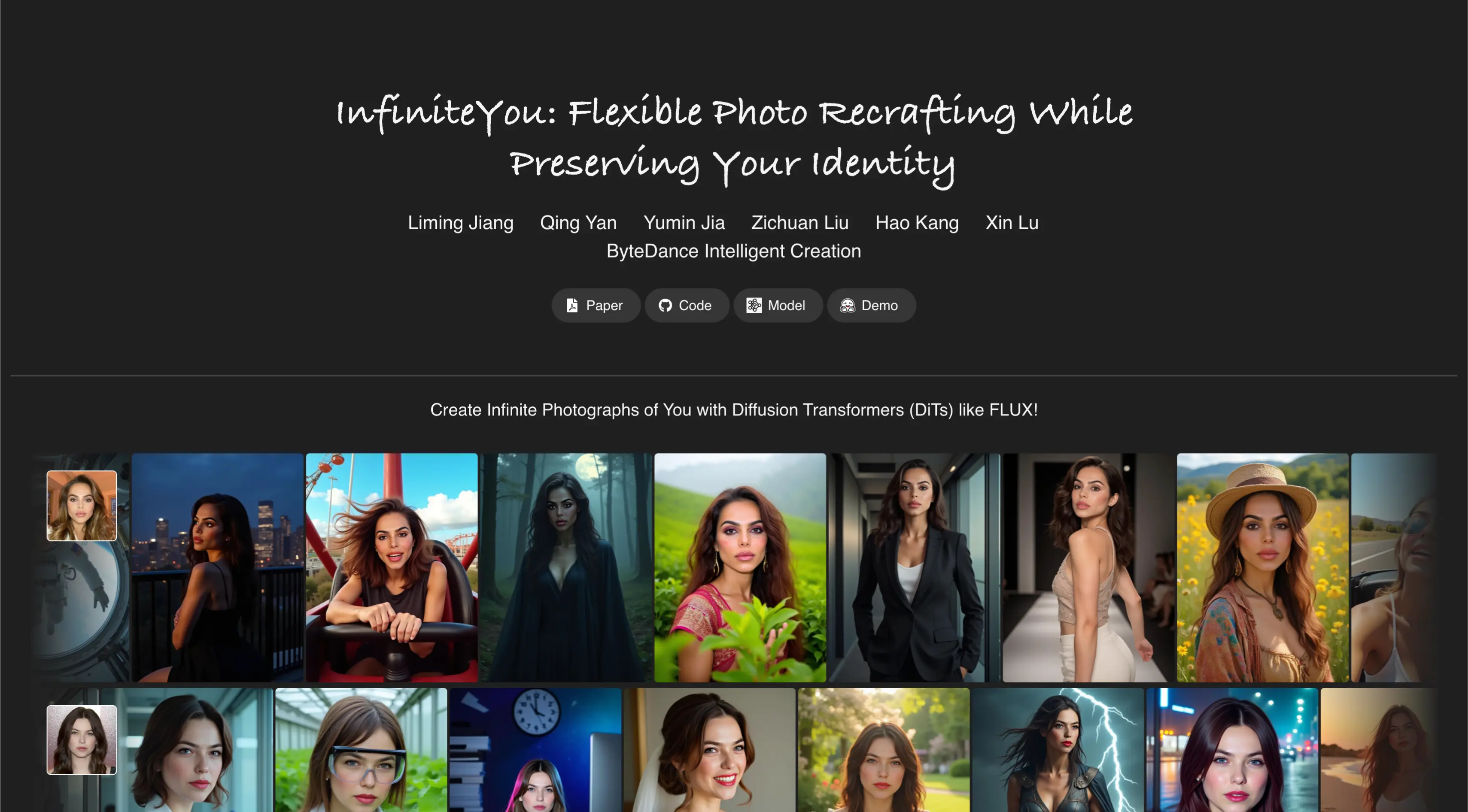
Have you ever imagined creating countless photos of yourself, each styled or themed differently, while keeping your face and identity intact? That’s exactly what InfiniteYou by ByteDance sets out to do.
In this article, I’ll walk you through everything you need to know about this AI model — how it works, its features, and how you can try it yourself.
What is InfiniteYou AI?
InfiniteYou is an image generation model developed by ByteDance. It is based on diffusion Transformer models and allows you to create multiple unique versions of yourself, guided by text prompts, while preserving your facial identity in each image.

This model goes beyond regular text-to-image generators — it ensures the output always keeps the essence of the original face, which has been a limitation for many other models.
Overview Table
| Feature | Details |
|---|---|
| Developed By | ByteDance |
| Model Type | Diffusion Transformer-based image generator |
| Key Component | InfuseNet |
| Key Strength | Maintains facial identity across generated images |
| Prompt Control | Yes (via text descriptions) |
| Optional Control Image Input | Yes |
| Code Availability | Open-source on GitHub |
| Platform Support | Hugging Face demo, local GPU setup |
| GPU Requirement | Not clearly mentioned, 40GB VRAM insufficient (likely needs 80GB+) |
Key Features of InfiniteYou
- Identity Preservation – Maintains the original facial identity in all generated outputs.
- Prompt-Based Customization – Describe the scene or setting in words, and the model generates a photo accordingly.
- InfuseNet Module – A new neural component that integrates facial features into the diffusion process.
- Supports Control Images – You can optionally add control images to influence pose or structure.
- Two-Stage Training Process – Starts with real images, then enhanced with synthetic samples.
- Open-Source – Code is available for anyone to experiment with (given sufficient hardware).
How is InfiniteYou Different?
Most existing diffusion models struggle with identity similarity, especially when generating creative images based on a face. Issues like poor alignment with the input prompt, unrecognizable or mismatched facial structure, and low image quality or unrealistic aesthetics are addressed by InfiniteYou through:
- Introducing InfuseNet for injecting identity features.
- Using residual connections to maintain both creativity and realism.
- Following a structured multi-stage training process that mixes real and synthetic data.
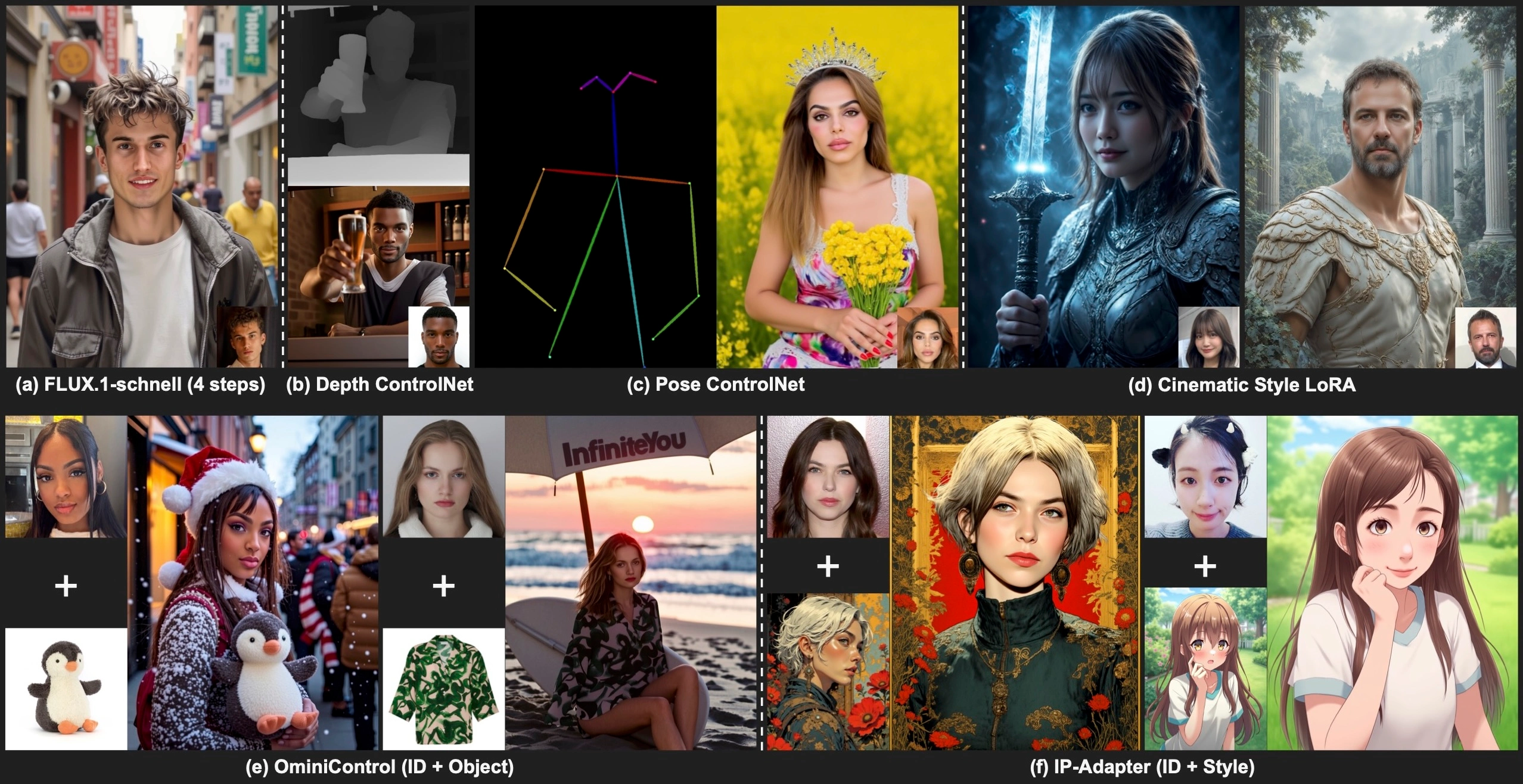
Step-by-Step Guide: How InfiniteYou Works
- Architecture Overview
At the heart of the InfiniteYou model lies InfuseNet, which works alongside a frozen base diffusion image Transformer.
Here’s how the components connect:- Identity Image ➝ passed through a face identity encoder
- Text Prompt ➝ passed through a frozen text encoder
- InfuseNet ➝ Receives identity features and optional control images
- Base Model ➝ Frozen model that takes noise + residuals from InfuseNet
- Block Structure
Let’s say the base model has M blocks and InfuseNet has N blocks.
Then M = N × I (I being a multiplication factor).
For instance, if N = 4 and I = 2, then base model has 8 blocks.
This structure allows InfuseNet to inject information periodically without overwhelming the base model. - Inputs and Flow
Input: Identity image, optional control image, and text description
Step-by-Step Flow:- Noise map is generated
- Identity image is converted into embeddings
- These embeddings are projected into InfuseNet
- Text description is embedded and fed to the base model
- InfuseNet sends intermediate features into the base model
- The final image is generated through denoising steps
- If no control image is provided, a black image is used by default.
Training Process
InfiniteYou was trained in two stages:
- Stage 1: Pre-Training with Real Images
Dataset: Real, single-person, single-sample images
Objective: Train the model to reconstruct identity images accurately
Approach:- Provide one photo per person
- Train the model to generate the same person using a descriptive caption
- Stage 2: Fine-Tuning with Synthetic Samples
After stage 1, synthetic data is generated using plugins like:- Lora enhancement modules
- Face swap modules
The model is then fine-tuned using these synthetic, diverse datasets
Result: Improved generalization and identity preservation
How to Use InfiniteYou AI
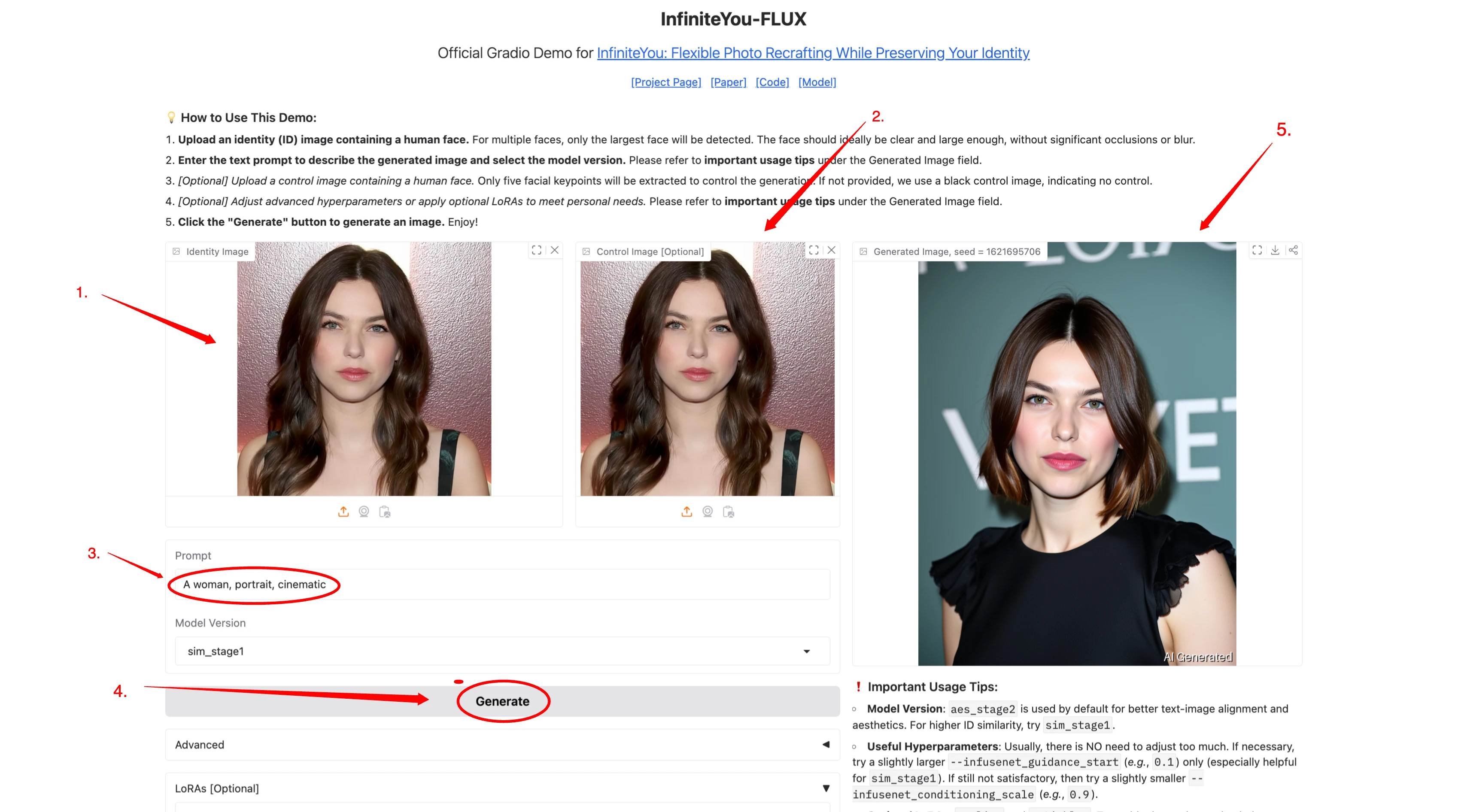
If you're interested in trying InfiniteYou, you have two main options:
- Option 1: Use Hugging Face Demo
ByteDance has released a demo on Hugging Face.
Upload your identity photo
Enter a prompt like: “young woman wearing medieval dress in a forest”
The model returns a photo with that context while keeping your face
Note: You might face GPU limits. The demo often runs out of capacity. - Option 2: Run It Locally (If You Have GPU)
Requirements (Approximate):- GPU: Likely 80GB VRAM required
- RAM: 64GB or more recommended
- Platform: Google Colab or local CUDA setup
- Repo: GitHub (Code Available)
- Clone the GitHub repository
- Install dependencies from requirements.txt
- Prepare your input image and prompt
- Run the inference code
Limitations and Suggestions
While InfiniteYou is powerful, there are a few things to note:
- No System Requirements: The GitHub page doesn’t mention exact GPU requirements.
- Heavy on Resources: You may need expensive GPUs or cloud credits to run it.
- Limited Public Access: The Hugging Face demo isn’t always available due to GPU caps.
Suggestion: ByteDance should consider adding minimum system requirements in their documentation.
Other ByteDance AI Image & Animation Tools
Final Thoughts
InfiniteYou by ByteDance is an impressive model if your goal is to create personal portraits that look like you — but in different styles, age groups, or scenarios. From smiling grandmas in gardens to futuristic warriors, all with your real face, InfiniteYou handles it beautifully.