What is OmniHuman-1?
OmniHuman is an end-to-end AI framework developed by researchers at ByteDance. It can generate incredibly realistic human videos from just a single image and a motion signal—like audio or video.
Whether it's a portrait, half-body shot, or full-body image, OmniHuman handles it all with lifelike movements, natural gestures, and stunning attention to detail.
At its core, OmniHuman is a multimodality-conditioned human video generation model. This means it combines different types of inputs, such as images and audio clips, to create realistic videos.
Overview of OmniHuman-1
| Feature | Description |
|---|---|
| AI Tool | OmniHuman-1 |
| Category | Multimodal AI Framework |
| Function | Human Video Generation |
| Generation Speed | Real-time video generation |
| Research Paper | arxiv.org/abs/2502.01061 |
| Official Website | https://omnihuman-lab.github.io/ |
OmniHuman-1 Guide
OmniHuman is an end-to-end multimodality-conditioned human video generation framework that can generate human videos based on a single human image and motion signals, such as audio only, video only, or a combination of both. For more advanced AI video generation tools, check out MagicVideo V2.
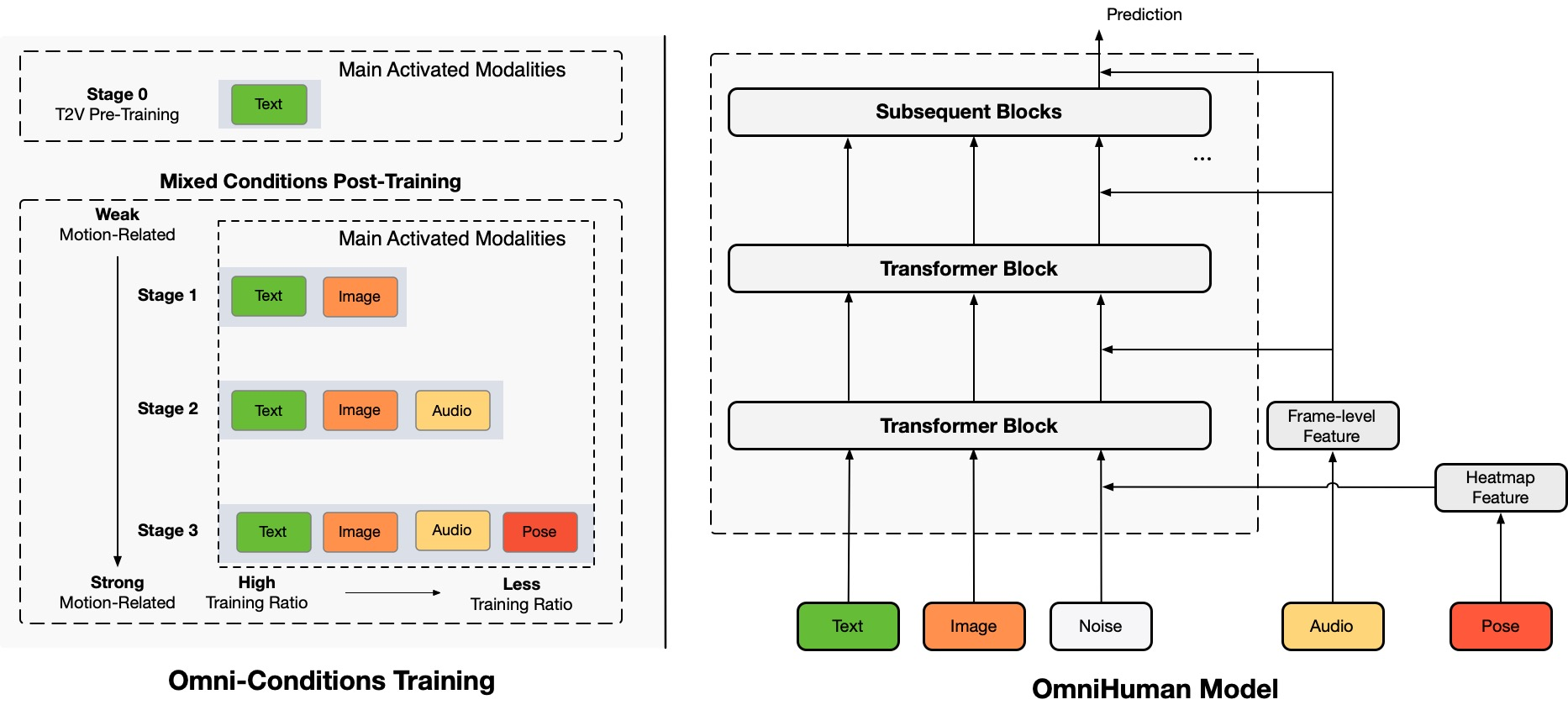
In OmniHuman, we introduce a multimodality motion conditioning mixed training strategy, allowing the model to benefit from data scaling up of mixed conditioning. This approach effectively overcomes the challenges faced by previous end-to-end methods due to the scarcity of high-quality data.
OmniHuman significantly outperforms existing methods, generating extremely realistic human videos based on weak signal inputs, especially audio.
How Does OmniHuman Work?
At its core, OmniHuman employs a diffusion-based framework that blends various conditioning signals to produce natural and realistic movements. Here’s a breakdown of its working process:
- Image and Motion Input Processing: OmniHuman takes an input image and motion signals (such as audio, video, or pose data) to analyze key facial and body features. The model extracts pose heatmaps, audio waveforms, and contextual movement cues to generate smooth animations.
- Diffusion Transformer Training: Using a powerful Diffusion Transformer (DiT) architecture, OmniHuman learns motion priors from large datasets. Unlike previous models that focused solely on facial animations, OmniHuman integrates whole-body movement generation, ensuring natural-looking gestures and lifelike interactions.
- Omni-Condition Training Strategy: One of the standout features of OmniHuman is its ability to efficiently scale up training data. Traditional models often discard a lot of training data due to inconsistencies, but OmniHuman retains valuable motion data by:
- Combining weaker conditions (audio) with stronger conditions (pose and video).
- Using multi-stage training that gradually integrates different motion elements.
- Employing a classifier-free guidance strategy to refine motion accuracy.
- Generating the Animated Video: Once trained, the model generates fluid, high-quality human videos that accurately match the input motion. OmniHuman supports arbitrary video lengths, multiple aspect ratios, and even artistic styles (such as cartoon or stylized character animation).
Key Features of OmniHuman-1
Multimodality Motion Conditioning
Combines image and motion signals like audio or video to create realistic videos
Realistic Lip Sync and Gestures
Precisely matches lip movements and gestures to speech or music, making the avatars feel natural.
Supports Various Inputs
Handles portraits, half-body, and full-body images seamlessly. Works with weak signals, such as audio-only input, producing high-quality results.
Versatility Across Formats
Can generate videos in different aspect ratios, catering to various content types.
High-Quality Output
Generates photorealistic videos with accurate facial expressions, gestures, and synchronization.
Animation Beyond Humans
Omnihuman-1 capable of animating cartoons, animals, and artificial objects for creative applications. Similar to MagicAvatar, it offers diverse animation possibilities.
Examples of OmniHuman-1 in Action
1. Singing
OmniHuman can bring music to life, whether it’s opera or a pop song. The model captures the nuances of the music and translates them into natural body movements and facial expressions. For instance:
- Gestures match the rhythm and style of the song.
- Facial expressions align with the mood of the music.
2. Talking
OmniHuman is highly skilled at handling gestures and lip-syncing. It generates realistic talking avatars that feel almost human. Applications include:
- Virtual influencers.
- Educational content.
- Entertainment.
OmniHuman supports videos in various aspect ratios, making it versatile for different types of content. For more AI avatar creation tools, explore DreamActor M1.

3. Cartoons and Anime
OmniHuman isn’t limited to humans. It can animate:
- Cartoons.
- Animals.
- Artificial objects.
This adaptability makes it suitable for creative applications, such as animated movies or interactive gaming.
4. Portrait and Half-Body Images
OmniHuman delivers lifelike results even in close-up scenarios. Whether it’s a subtle smile or a dramatic gesture, the model captures it all with stunning realism.
5. Video Inputs
OmniHuman can also mimic specific actions from reference videos. For example:
- Use a video of someone dancing as the motion signal, and OmniHuman generates a video of your chosen person performing the same dance. Check out DanceTrack for advanced dance motion tracking.
- Combine audio and video signals to animate specific body parts, creating a talking avatar that mimics both speech and gestures.
Pros and Cons
Pros
- High Realism
- Versatile Input
- Multimodal Functionality
- Broad Applicability
- Works with Limited Data
Cons
- Limited Availability
- Resource Intensive
- Requires significant computational power
How to Use OmniHuman-1?
Step 1: Input
You start with a single image of a person. This could be a photo of yourself, a celebrity, or even a cartoon character. Then, you add a motion signal, such as an audio clip of someone singing or talking.
Step 2: Processing
OmniHuman employs a technique called multimodality motion conditioning. This allows the model to understand and translate the motion signals into realistic human movements. For example:
- If the audio is a song, the model generates gestures and facial expressions that match the rhythm and style of the music.
- If it’s speech, OmniHuman creates lip movements and gestures synchronized with the words.
Step 3: Output
The result is a high-quality video that looks like the person in the image is actually singing, talking, or performing actions described by the motion signal. OmniHuman excels even with weak signals like audio-only input, producing realistic results.
Applications of OmniHuman
The potential applications for OmniHuman are vast and varied:
- Entertainment: Filmmakers and game developers can resurrect historical figures or create virtual characters that interact seamlessly with real actors, enriching storytelling possibilities. Learn more about OmniHuman use cases in entertainment.
- Education: Educators can develop engaging content where historical personalities deliver lectures or explanations, making learning more interactive and captivating.
- Marketing: Brands can craft personalized advertisements featuring virtual ambassadors that resonate with target audiences, enhancing brand engagement.
How does OmniHuman-1 compare to other AI animation tools?
OmniHuman-1, developed by ByteDance, stands out as a revolutionary AI animation tool in comparison to other AI systems like Synthesia, Sora, and Veo. Here’s how it compares across key dimensions:
- Input Flexibility
OmniHuman-1: Accepts a wide range of inputs, including audio, text, video, and pose signals, enabling seamless multimodal integration.
Competitors: Typically limited to specific modalities, such as text or video, which restricts their versatility. - Animation Scope
OmniHuman-1: Capable of generating full-body animations with lifelike gestures, gait, and synchronized speech. It excels in creating fluid movements for entire human figures.
Competitors: Focus primarily on facial or upper-body animations, limiting their ability to create holistic human representations. - Realism and Accuracy
OmniHuman-1: Utilizes advanced technologies like Diffusion Transformers (DiT) and 3D Variational Autoencoders (VAE) to ensure temporal coherence and naturalistic motion. It also incorporates classifier-free guidance for better adherence to input cues.
Competitors: Often rely on smaller datasets and simpler architectures, leading to less realistic outputs in terms of motion and lip-sync accuracy. - Data and Training Efficiency
OmniHuman-1: Trained on 18,700+ hours of diverse video footage using an "omni-condition" strategy, allowing it to handle various aspect ratios and body proportions with ease.
Competitors: Operate on smaller, filtered datasets that limit their adaptability to different scenarios. - Applications
OmniHuman-1: Supports a broad range of use cases—from gaming and virtual influencers to education and healthcare—thanks to its ability to animate entire bodies in any style or proportion.
Competitors: More specialized in creating stylized outputs for professional videos or specific industries but lack the flexibility for full-body animations.
What Is Seedance AI?
Seedance AI is ByteDance’s latest release in the space of AI-generated video tools. It’s designed to turn both text and image prompts into high-quality, cinematic video clips.
According to the independent leaderboard by Artificial Analysis, Seedance AI is currently the top-ranked model, outperforming even Google’s powerful Veo 3.
Performance: Leaderboard Rankings
Seedance is currently ranked above Google's V3 model in both text-to-video and image-to-video benchmarks. It has a significantly higher ELO score, outperforming V3 by as much as 100 points in some image-to-video tests.
This is impressive considering Veo 3 has long held a reputation for accuracy and style.
How to Use Seedance AI (Mini)
Here’s a basic walkthrough of how to start using Seedance Mini via Dreamina:
Step-by-Step Guide:
- Visit the Dreamina Platform: Head to the link provided in the official demo description.
- Sign In or Register: Create an account to access generation tools.
- Choose Prompt Type:
- Text-to-video: Write a scene in natural language.
- Image-to-video: Upload an image and add a description.
- Set Output Preferences:
- Aspect ratio (Vertical, Square, Horizontal)
- Duration
- Style (Pixel art, Anime, Photorealism)
- Submit & Generate: Wait for processing. Depending on complexity, results may take a few minutes.
- Download or Share: Save your video or share it directly on social platforms.