ByteDance Dolphin – Document Image Parsing Model

ByteDance has been consistently releasing impressive models. Just a couple of days ago, they launched the Bagel model, and now we have another model called Dolphin. This model is designed to read and understand complex documents such as research papers, reports, or forms that contain a mix of text, images, tables, and mathematical formulas.
In this guide, I’ll walk you step by step through what Dolphin is, how it works, its key features, and how to install and test it locally. I’ll also demonstrate how it handles different document elements like text, tables, and formulas.
What is ByteDance Dolphin?
Dolphin is a document image parsing model. You can think of it as a sophisticated reading system with two primary tasks:
- Document Layout Understanding
It first looks at the entire page to figure out the structure and reading order. Similar to how you might scan a newspaper to identify the layout, Dolphin identifies where the text, tables, and images are placed and how they should be read. - Content Extraction
After understanding the structure, it dives into specific sections to extract the actual content—whether it’s plain text, a table, or even a formula.
This two-step approach makes Dolphin highly accurate at handling complicated documents. Instead of attempting everything at once, it separates layout recognition from content extraction.
Dolphin Model Overview
The Dolphin model works like a reading machine. It has two key components that work together:
- Vision Encoder (Swin Transformer): A type of neural network that processes images in small patches. This component acts as the "eyes" of the system, examining the document image and extracting visual details.
- Text Decoder (mBART): A multilingual neural network used for converting extracted information into readable text across different languages. This acts as the "brain," interpreting what the encoder sees and converting it into structured text.
Key Highlights:
- You can give instructions in plain English or Chinese.
- You can specify what type of content you want to extract—text, table, or formula.
- It outputs results in Markdown and JSON formats, making it useful for structured datasets.
Dolphin Model Architecture
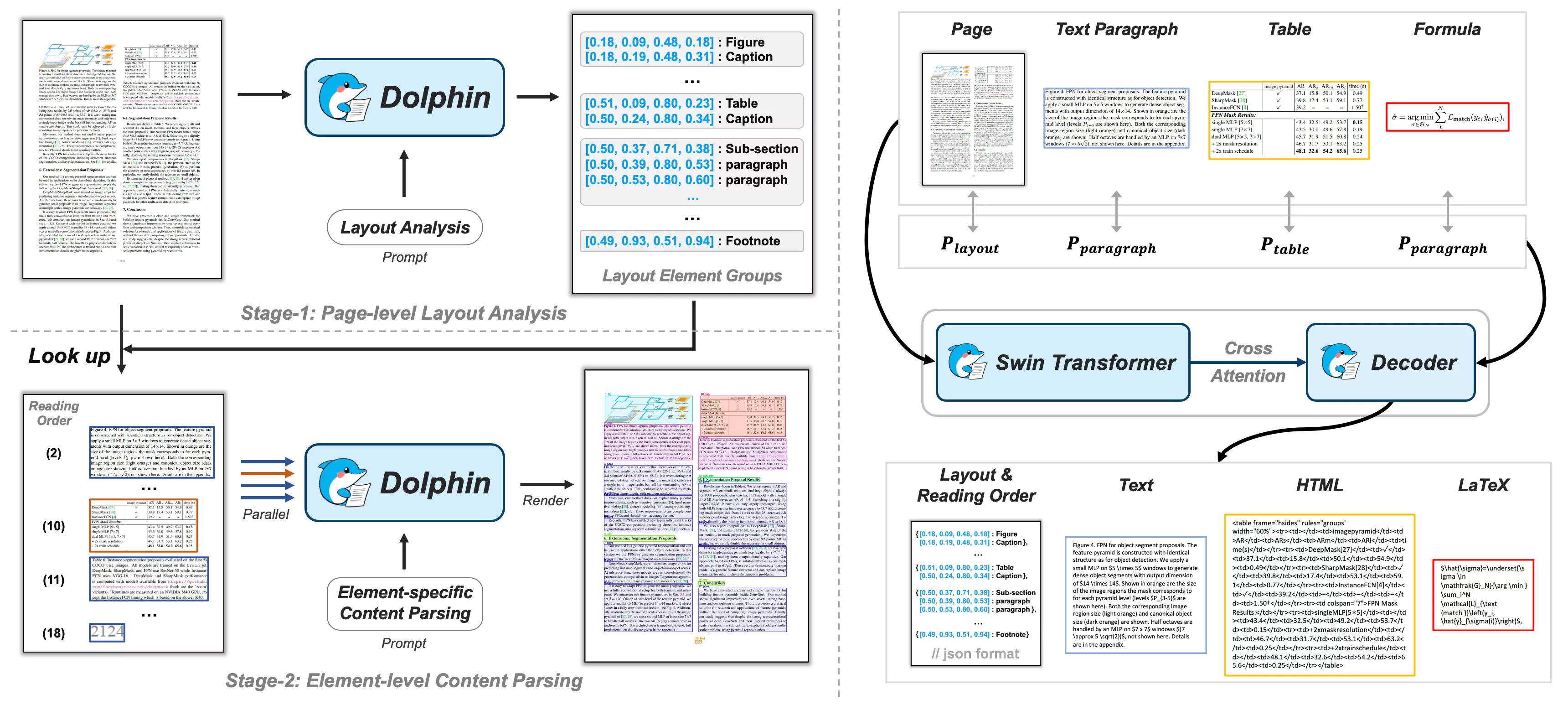 Figure: Dolphin model framework overview
Figure: Dolphin model framework overviewInstallation Guide
Now let’s move on to installing Dolphin locally. I performed this installation on an Ubuntu system using an Nvidia RTX 6000 GPU with 48GB VRAM.
Here’s the step-by-step process:
- Step 1: Create a Virtual Environment
python3 -m venv dolphin_env source dolphin_env/bin/activate
- Step 2: Clone the Repository
git clone <Dolphin-repo-link> cd Dolphin
- Step 3: Install Requirements
pip install -r requirements.txt
This process may take a few minutes depending on your system. - Step 4: Login to Hugging Face
huggingface-cli login
Paste your Hugging Face token (free to generate in your profile). - Step 5: Download the Model
huggingface-cli repo download bytedance/dolphin-model
That’s it—the model is ready to use.
Testing Dolphin Locally
Once installed, I ran Dolphin on several document types. Here’s what I found.
Extracting Text from a Document
The first test was on a JPEG page image where I wanted to extract all text. Using the provided script:
python run_dolphin.py --model_path ./dolphin --image_path ./sample.jpg --output_dir ./results
The results were extremely fast. The output included:
- Markdown File: neatly formatted and accurate.
- JSON File: structured key-value pairs based on page elements.
The results showed almost no mistakes, delivering high-quality outputs comparable to other top models like IBM’s Dockling.
Extracting Tables
Next, I tested Dolphin on a page containing a table. This time, I instructed the model to process only table elements:
python run_dolphin.py --element_type table
Results:
- Markdown output displayed the table structure perfectly, even maintaining formatting like brackets and dots.
- JSON output presented the table element-by-element with labels and text values.
- The VRAM consumption was just a little over 2 GB, meaning this model can easily run on CPUs or smaller GPUs too.
Extracting Formulas
The next test involved extracting mathematical formulas.
python run_dolphin.py --element_type formula
Results:
- Markdown format preserved boxed layouts perfectly.
- JSON format clearly separated text and labels.
- Processing speed was very fast (around 7 seconds).
- The model performed spot-on in formula recognition.
Extracting Paragraphs
Finally, I tested extracting a specific paragraph from the document.
Initially, I gave it the wrong paragraph ID (par 1 instead of par 2), so the extraction failed. After correcting the ID, the results were excellent. The output included:
- Markdown with well-preserved formatting.
- JSON with clean line breaks.
- Even detailed checks showed accurate extraction of specific sentences.
Key Features of Dolphin
Here’s a quick summary of what Dolphin offers:
- Two-Part Architecture: Vision encoder (Swin Transformer) + text decoder (mBART).
- Multi-Language Support: Instructions in English or Chinese.
- Element-Specific Extraction: Choose to extract full page, tables, formulas, or paragraphs.
- Output Formats: Markdown and JSON.
- Lightweight: Runs even without GPU, but GPU speeds up processing.
- Fast Processing: Extracts document elements within seconds.
Table: Dolphin Overview
| Feature | Description |
|---|---|
| Developer | ByteDance |
| Model Type | Document Image Parsing |
| Encoder | Swin Transformer (vision encoder) |
| Decoder | mBART (multilingual text decoder) |
| Input | Images of documents |
| Output | Text, tables, formulas (Markdown & JSON) |
| Language Support | English, Chinese |
| GPU Requirement | Optional (runs on CPU as well) |
How to Use Dolphin (Step-by-Step)
- Install dependencies and set up a virtual environment.
- Login to Hugging Face and download the model.
- Run Dolphin on a document image using provided scripts.
- Choose extraction type (text, table, formula, paragraph).
- Check outputs in the results directory (Markdown or JSON).
- Compare extracted content with the original image if needed.
FAQs
- What makes Dolphin different from other models?
It combines a Swin Transformer for layout understanding and mBART for multilingual decoding. This makes it effective for structured document parsing. - Do I need a GPU to run Dolphin?
No. While GPU speeds up processing, Dolphin can run efficiently on CPU as well. - Which file formats does Dolphin accept?
It works with document images (e.g., JPEG, PNG). - What output formats does Dolphin provide?
Outputs are generated in Markdown and JSON formats. - Can Dolphin extract only specific elements?
Yes, you can specify whether you want text, a table, a formula, or a paragraph. - How accurate is Dolphin?
In my tests, accuracy was excellent. Minor issues may occur if incorrect element IDs are used, but overall performance is at par with top models.
Final Thoughts
ByteDance Dolphin is an impressive step forward in document parsing. It successfully extracts complex elements like tables and formulas with accuracy, outputs results in structured formats, and runs efficiently even without a high-end GPU.
In my testing, Dolphin consistently delivered high-quality outputs, showing potential for use in dataset creation, research analysis, and structured content extraction.
ByteDance seems to be making consistent progress in releasing powerful models. The earlier Bagel model was impressive, and Dolphin further proves their commitment to practical AI tools.