How NUMINA Uses Human Embodiment Data to Improve Robot Manipulation
What is How NUMINA Uses Human Embodiment Data to Improve Robot Manipulation
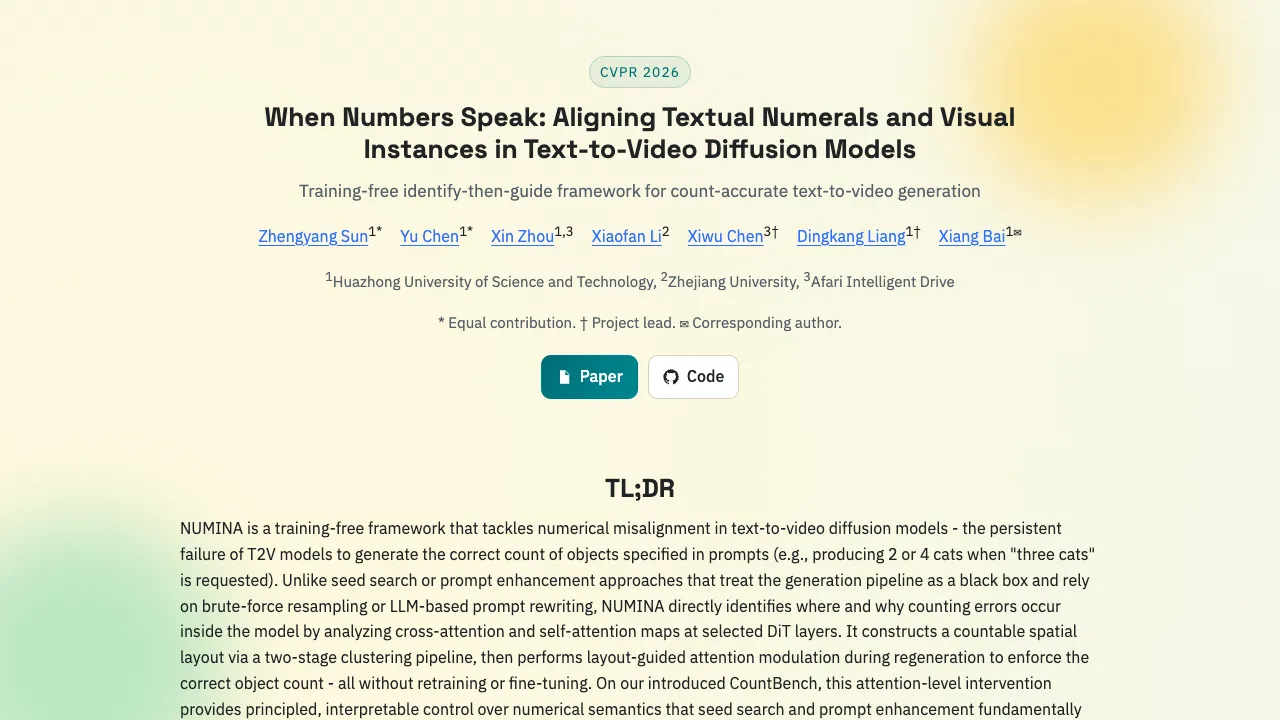
NUMINA is a simple add on that helps text to video models follow numbers in your prompt. If you ask for three cats, it works to show three cats instead of two or four. It does this without retraining the base model.
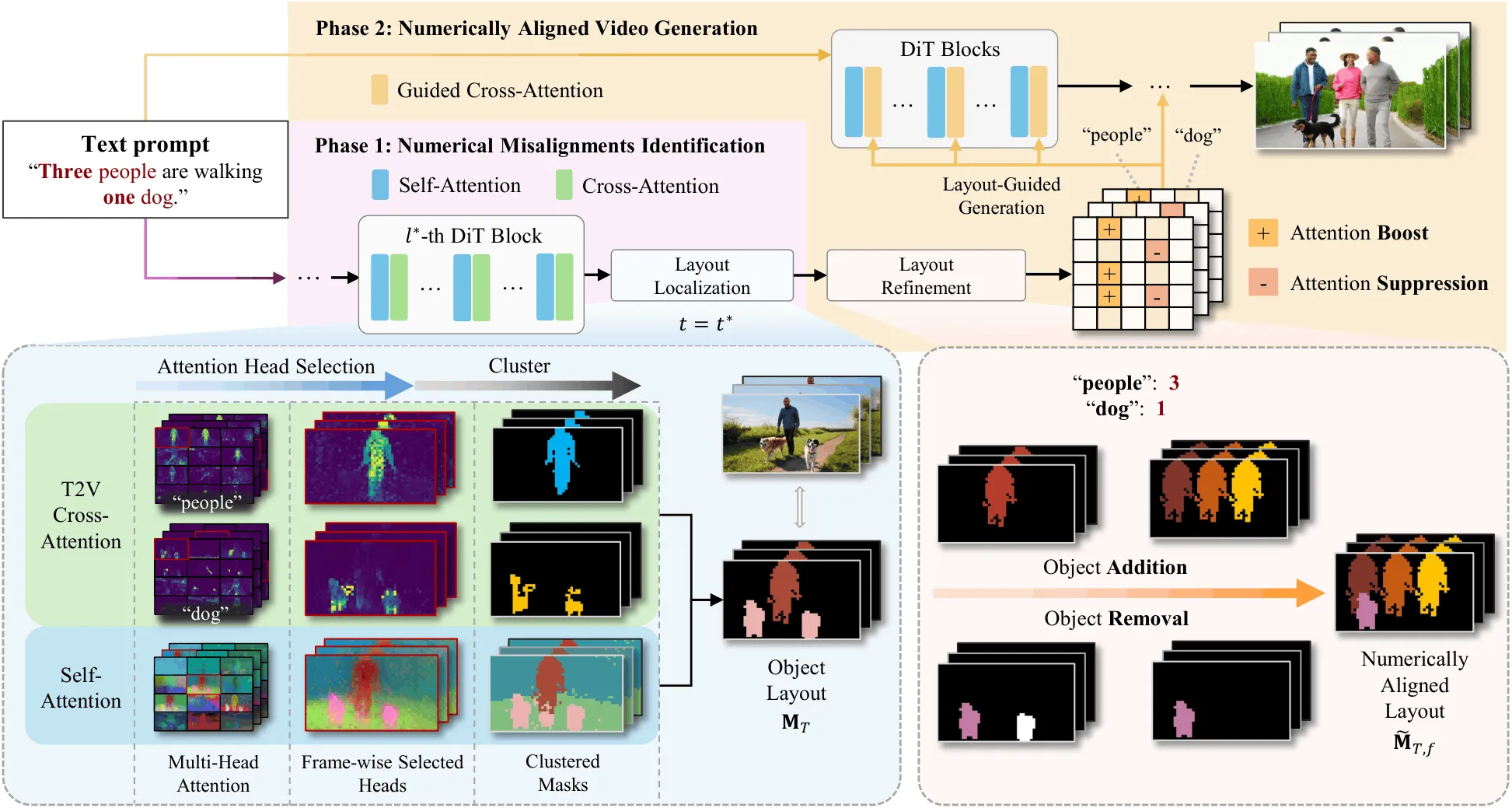
NUMINA reads the model’s attention maps to find where counting errors start. It then builds a simple layout of where each object should be and guides the model to match the exact count during a second pass. The team shows clear gains on their CountBench tests and across several Wan 2.1 model sizes.
NUMINA Overview
Here is a quick look at the project details.
| Item | Details |
|---|---|
| Type | Training free add on for text to video diffusion models |
| Purpose | Make the number of objects in the video match the numbers in the prompt |
| Main features | Finds counting errors from attention maps, builds a countable layout, guides a second pass to correct counts, no retraining, works with EasyCache, simple command line use |
| Works with | Wan 2.1 text to video models at 1.3B, 5B, and 14B sizes |
| Input | A text prompt with clear numerals and nouns, for example “Three men are walking in the park.” |
| Output | A video with the requested number of objects while keeping the scene and motion |
| Accuracy gains | Up to 7.4 percent better counting on Wan 2.1 1.3B in CountBench tests |
| Install steps | Clone Wan2.1 and NUMINA, copy module files, pip install requirements |
| Quick start | One line command with —numina and noun counts in JSON |
| Code | GitHub repository and simple folder add on inside Wan 2.1 |
| Demo | Side by side videos that compare baseline and NUMINA |
| Best for | Prompts that need strict counts of people, animals, and items |
| Website | Project page with demos and notes |
| Status | Research code from the H EmbodVis team |
| License | Not specified in the provided notes |
Read More: Bytedance
NUMINA Key Features
- Training free add on that plugs into Wan 2.1. No model fine tune is needed.
- Two phase flow. First find a layout with the right count, then guide the second pass to match it.
- Attention guided control. It looks at both cross attention and self attention at chosen layers to spot count gaps.
- Countable layout. It uses a two stage clustering method to locate object slots you can count.
- Works with speed up tools. It supports EasyCache during the first phase to save time.
- Cross model use. Shown on Wan 2.1 at 1.3B, 5B, and 14B.
- Simple CLI. You can pass noun to count pairs.
NUMINA Use Cases
- Ads and media teams that need a fixed number of people or props in a clip.
- Education clips where prompts like “Four planets orbit the star” must be exact.
- Dataset creation where strict counts matter for later use.
If you are exploring real world task control, you may also like our short guide on robot skills here: Gr1 Manipulation.
How it works
NUMINA runs in two steps. First, it scans attention maps to see how the model spreads focus across words and frames. It picks the heads that best separate the target noun and clusters those maps into a clean, countable layout.
Second, it refines the layout a bit to avoid splits or merges. Then it guides cross attention during a new generation pass so that the video shows the right number of items in the right places.
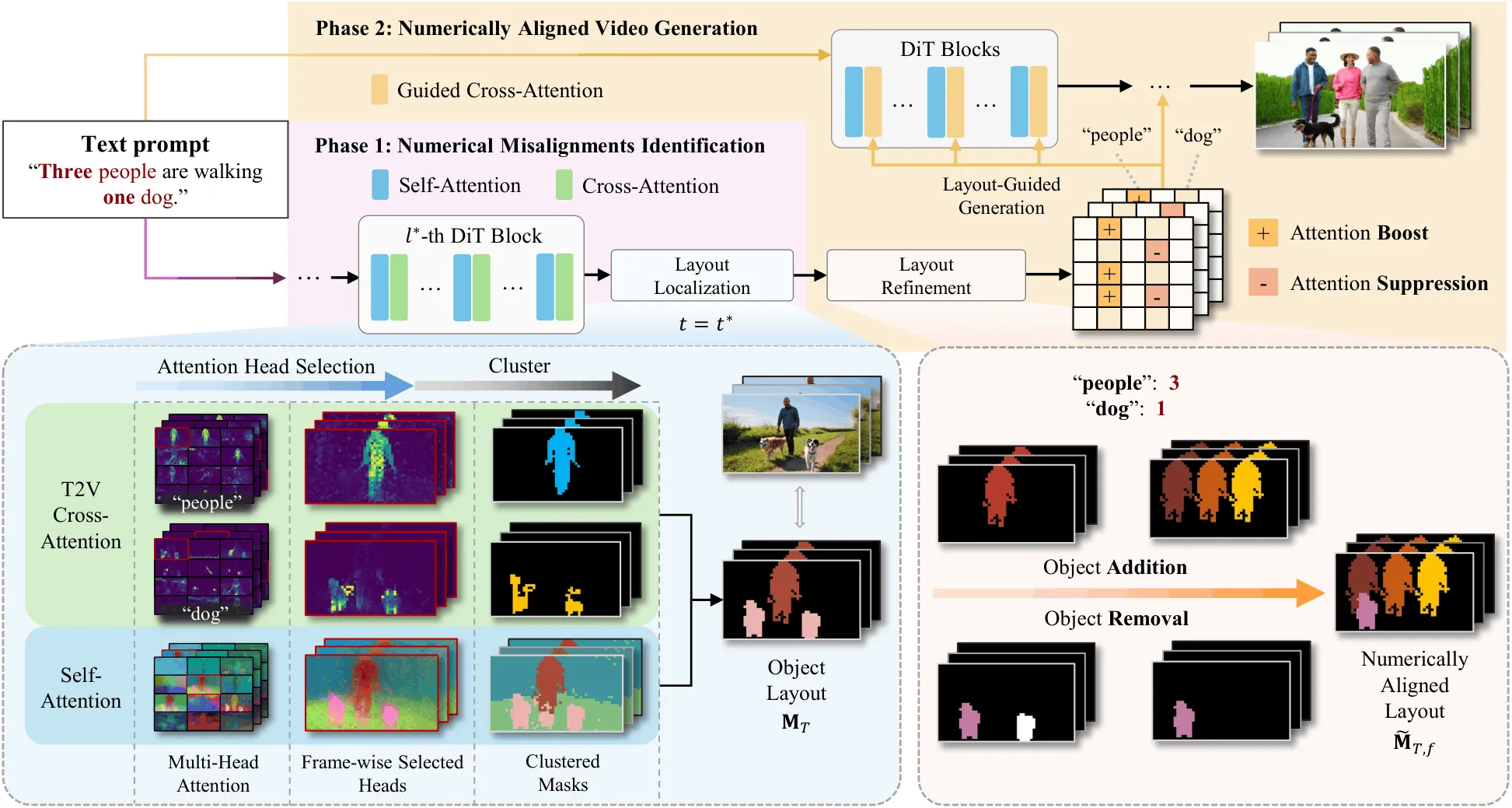
The technology behind it
- Attention head selection: it scores attention heads that best track the target noun tokens.
- Layout building: it applies MeanShift and DBSCAN in a simple two step flow to get clean, countable regions.
- Attention modulation: it adds small biases in cross attention during the second pass so the model follows the layout.
- EasyCache support: phase one can reuse transformer outputs to speed up inference.
If you care about data quality topics tied to model outputs, see this short read: Phantom Data.
Installation and setup
Follow these steps exactly as given in the project.
# Clone Wan2.1 repo
git clone https://github.com/Wan-Video/Wan2.1.git
cd Wan2.1
# From within the Wan2.1 root directory
git clone https://github.com/H-EmbodVis/NUMINA.git numina_repo
# Copy NUMINA modules
cp -r numina_repo/numina ./numina
# Apply modifications to Wan2.1 files
cp numina_repo/wan/modules/attention.py ./wan/modules/attention.py
cp numina_repo/wan/modules/model.py ./wan/modules/model.py
cp numina_repo/wan/text2video.py ./wan/text2video.py
cp numina_repo/generate.py ./generate.py
# install dependencies
pip install -r numina_repo/requirements.txt
Please follow the Wan2.1 README for model checkpoint downloads and any platform specific setup for example FlashAttention.
Project structure
Here is how the added files fit into Wan 2.1.
Wan2.1/
├── ...
├── numina/ # NUMINA modules (new)
├── __init__.py
├── config.py # All hyperparameters
├── token_mapper.py # Nouns → T5 token index mapping
├── head_selection.py # attention head scoring
├── layout.py # MeanShift + DBSCAN layout pipeline
└── modulation.py # Cross-attention bias for SDPA
├── wan/
├── ...
├── modules/
│ ├── ...
│ ├── attention.py # Modified: extraction + modulation paths
│ └── model.py # Modified: NUMINA state propagation
└── text2video.py # Modified: two-phase pipeline
└── generate.py # Modified: --numina CLI arguments
Modified Wan 2.1 files in four places.
- wan/modules/attention.py adds manual attention for extraction and SDPA for modulation
- wan/modules/model.py adds NUMINA state management and routing
- wan/text2video.py adds generate_numina two phase pipeline with EasyCache integrated
- generate.py adds NUMINA CLI arguments
Getting started
Here is the quickest way to try it.
python generate.py \
--task t2v-1.3B \
--ckpt_dir /path/to/Wan2.1-T2V-1.3B \
--prompt "Three men are walking in the park." \
--numina \
--numina_noun_counts '{"men": 3}' \
--size 832*480
NUMINA specific arguments exist for offload options, T5 on CPU, guide scale, seeds, and more. Please refer to the Wan 2.1 docs for the full list.
Tips for better prompts
Keep the noun clear and countable. Use simple nouns like men, cats, cars, or books. Add action and place words after the count part.
For more on companies building across media and AI, here is a light read: Bytedance.
Performance and showcases
Below are short side by side clips that compare outputs.
Showcase 1 — Wan2.1-1.3B(Baseline) This clip shows Wan2.1-1.3B(Baseline) for Case 1. Use it to see the original count behavior before NUMINA.
Showcase 2 — NUMINA This clip shows NUMINA for Case 1 using the same prompt. Check how the object count matches the number in the text.
Showcase 3 — Wan2.1-1.3B(Baseline) This clip shows Wan2.1-1.3B(Baseline) for Case 2. You can compare counts against the label that the text requests.
Showcase 4 — NUMINA This clip shows NUMINA for Case 2 using the same prompt. Look for tighter match between the prompt number and the final video.
Showcase 5 — Wan2.1-1.3B(Baseline) This clip shows Wan2.1-1.3B(Baseline) in a further Case 1 from the addition set. Note any extra or missing objects.
Showcase 6 — NUMINA This clip shows NUMINA for the same Case 1. See how the count aligns with the requested number.
FAQ
Does NUMINA change my base model or retrain it
No. It adds a light module and a two step process. It does not retrain or fine tune the base model.
What prompts work best
Prompts with clear numerals and nouns work best. For example “Four students reading books under the tree” or “Two kittens playing with two yarn balls.”
Can NUMINA work with larger Wan 2.1 models
Yes. The team shows gains on 5B and 14B sizes too. The same flow applies.
What if my noun is not in the token map
Use a simple noun or a close synonym that maps well to T5 tokens. Then set the noun to count pair in the command line.
How to read the demos on the project page
Look at the label and the noun in the prompt first. Then check if the number of objects matches in the video.
If you are comparing outputs across tasks in your pipeline, our short note on data issues may help: Phantom Data.
Image source: How NUMINA Uses Human Embodiment Data to Improve Robot Manipulation