Phantom-Data: Revolutionizing Subject-Consistent Video Generation

What is Phantom-Data: Subject-Consistent Video Generation
Phantom-Data is a very large and carefully built dataset that helps video AI keep the same person or object consistent across frames, while still following the text prompt well. It fixes a common issue where models “copy and paste” the background or scene from the reference image, instead of truly following the prompt.
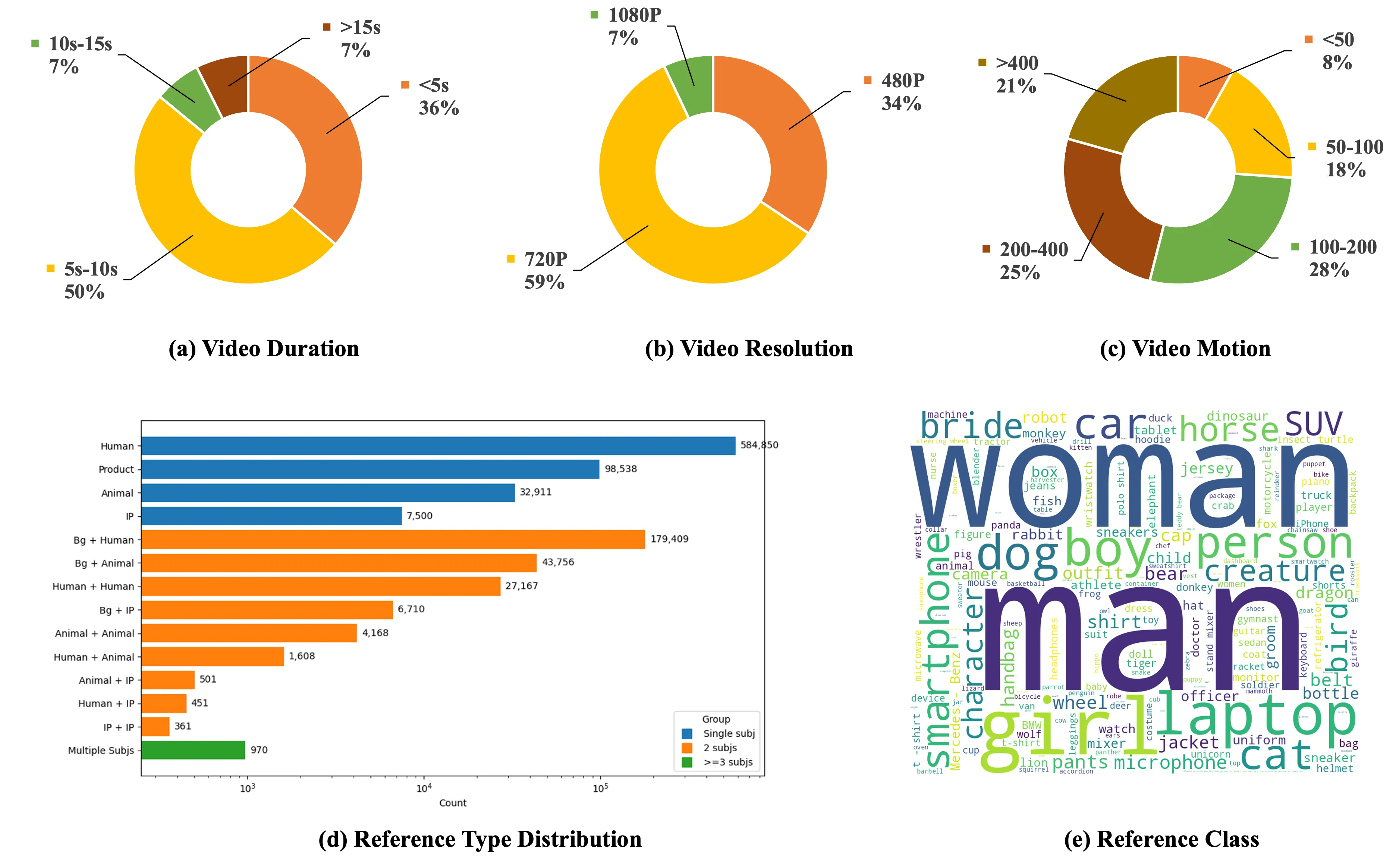
It does this by pairing images and videos of the same subject from different places and times, so the model learns identity without sticking to one scene. The team collected about one million identity-consistent pairs and verified them across many settings.
Read More: Text To Video
Phantom-Data: Subject-Consistent Video Generation Overview
Here is a quick snapshot of the project.
| Field | Details |
|---|---|
| Type | Cross-pair subject-to-video dataset and inference toolkit |
| Purpose | Keep the same subject identity in generated videos while following text prompts |
| Main Features | ~1M identity-consistent pairs; cross-context retrieval; prior-guided ID checks; strong prompt following |
| Data Sources | Over 53M videos and 3B images scanned for cross-context identity matches |
| Models | Phantom-Wan-1.3B and Phantom-Wan-14B for subject-to-video generation |
| Inputs | Text prompt + 1 to 4 reference images |
| Outputs | Consistent subject-to-video results at up to 720p (with notes) |
| Framework | Works on top of Wan2.1; uses redesigned text-image injection and triplet alignment |
| Team | Intelligent Creation Team, Bytedance |
| Status | Paper and demos available; data construction explained; model checkpoints released for inference |
| Requirements | torch >= 2.4.0; huggingface-cli; optional multi-GPU with FSDP |
Phantom-Data: Subject-Consistent Video Generation Key Features
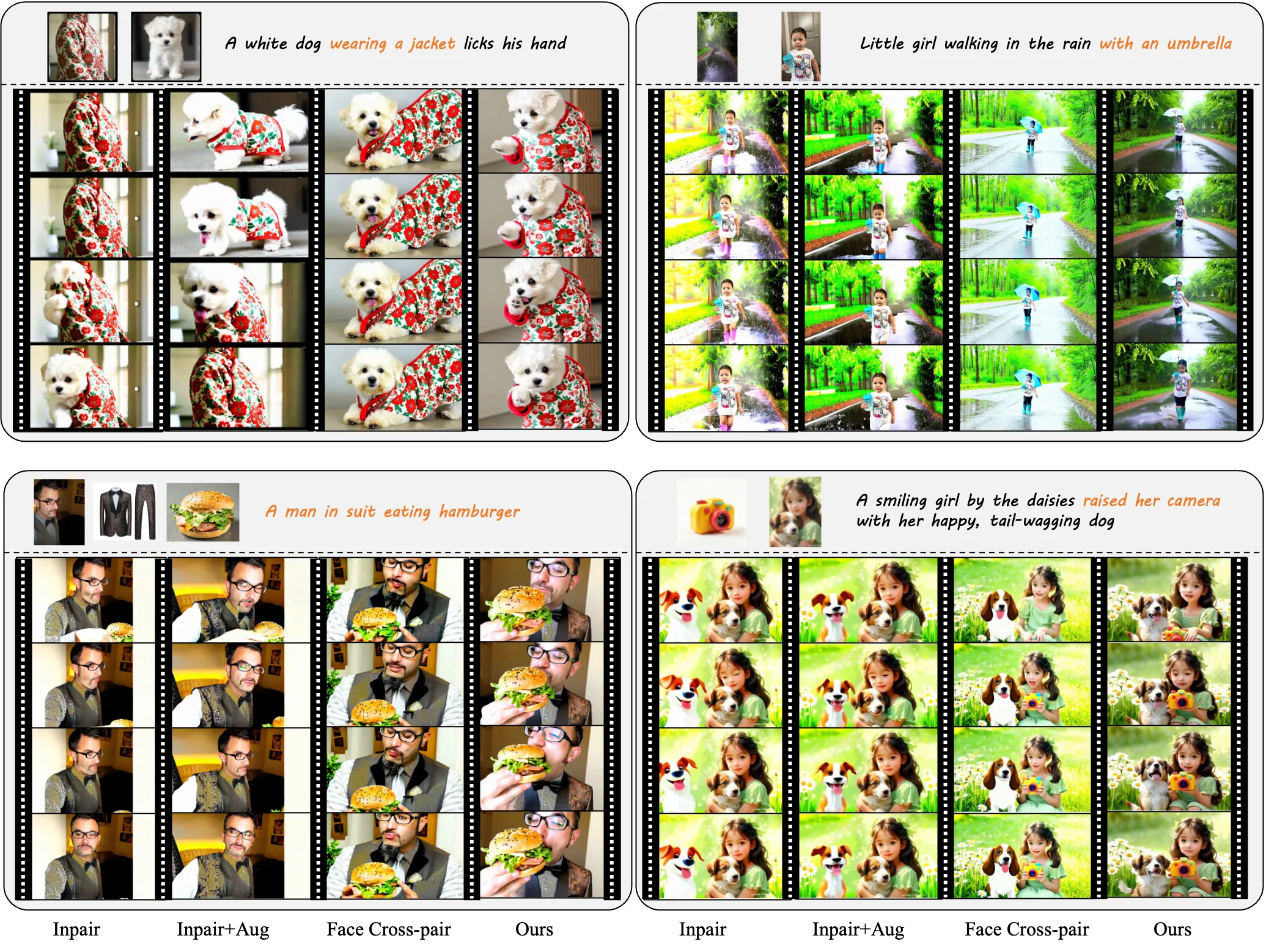
- Cross-pair identity training: The subject is matched across different scenes to avoid scene “copy-paste.”
- Big and rse: About one million high-quality pairs from many categories and contexts.
- Three-stage build: Detect subject, retrieve cross-context pairs, then verify identity carefully.
- Works with text prompts: Keeps identity while following prompt details better than in-pair training.
- Scales to different models: Comes with Phantom-Wan-1.3B and Phantom-Wan-14B examples for video generation.
How Phantom-Data Works
The team uses a simple pipeline with three parts. First, a subject-centric detection module finds the person or object that matters in each image or frame. Second, a large search system looks through 53M videos and 3B images to find the same subject in different places. Third, a prior-guided ID check confirms the match so the pair is truly identity-consistent.
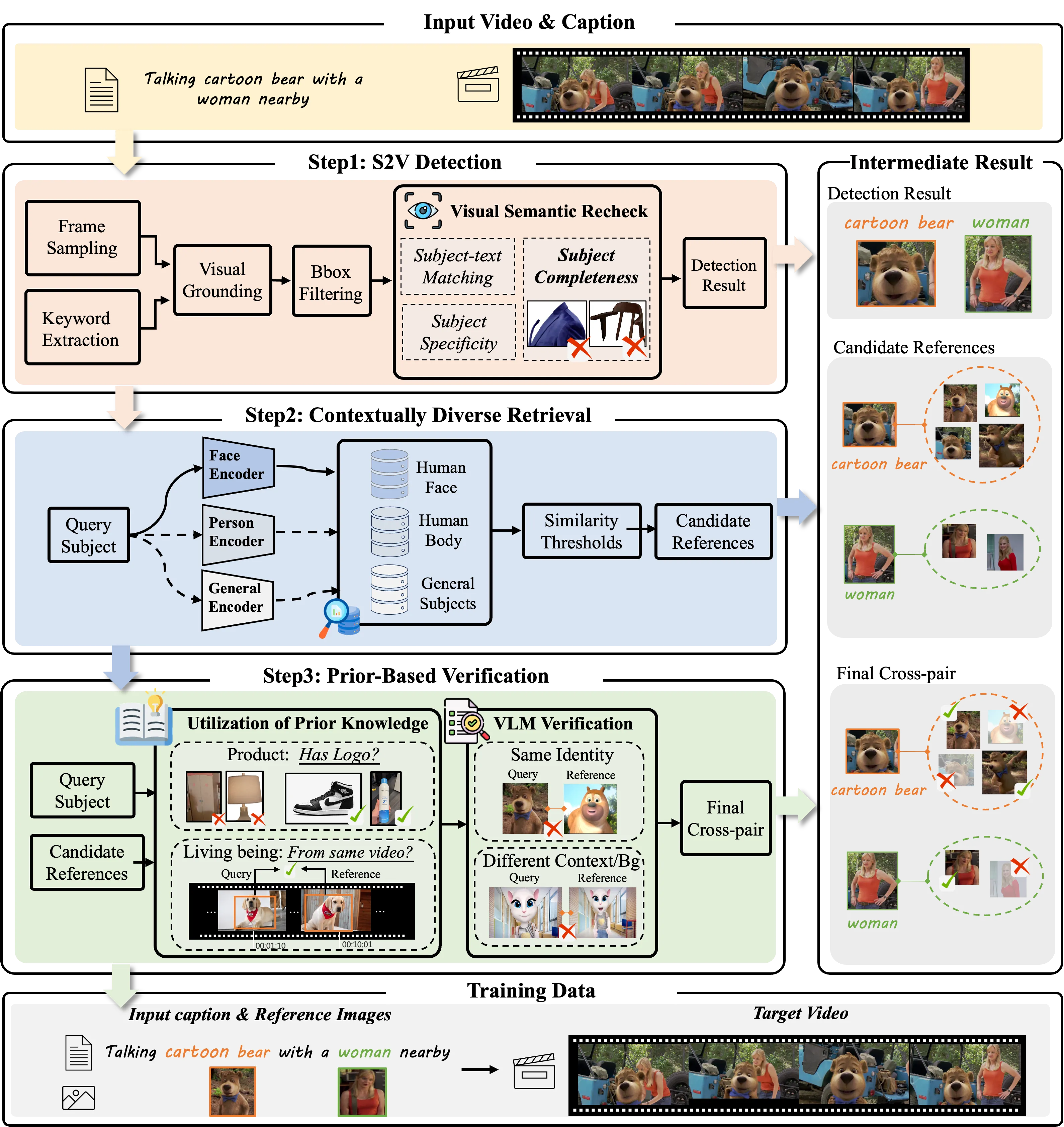
This cross-context pairing means the subject stays the same, but the background, pose, or outfit can vary. That trains models to follow prompts while keeping the subject’s identity across frames.
Read More: Dancetrack
Why Real Pairs Beat Synthetic Data
The team tested training with different data choices. They show that using real cross-pair matches leads to better prompts and strong ID stability.
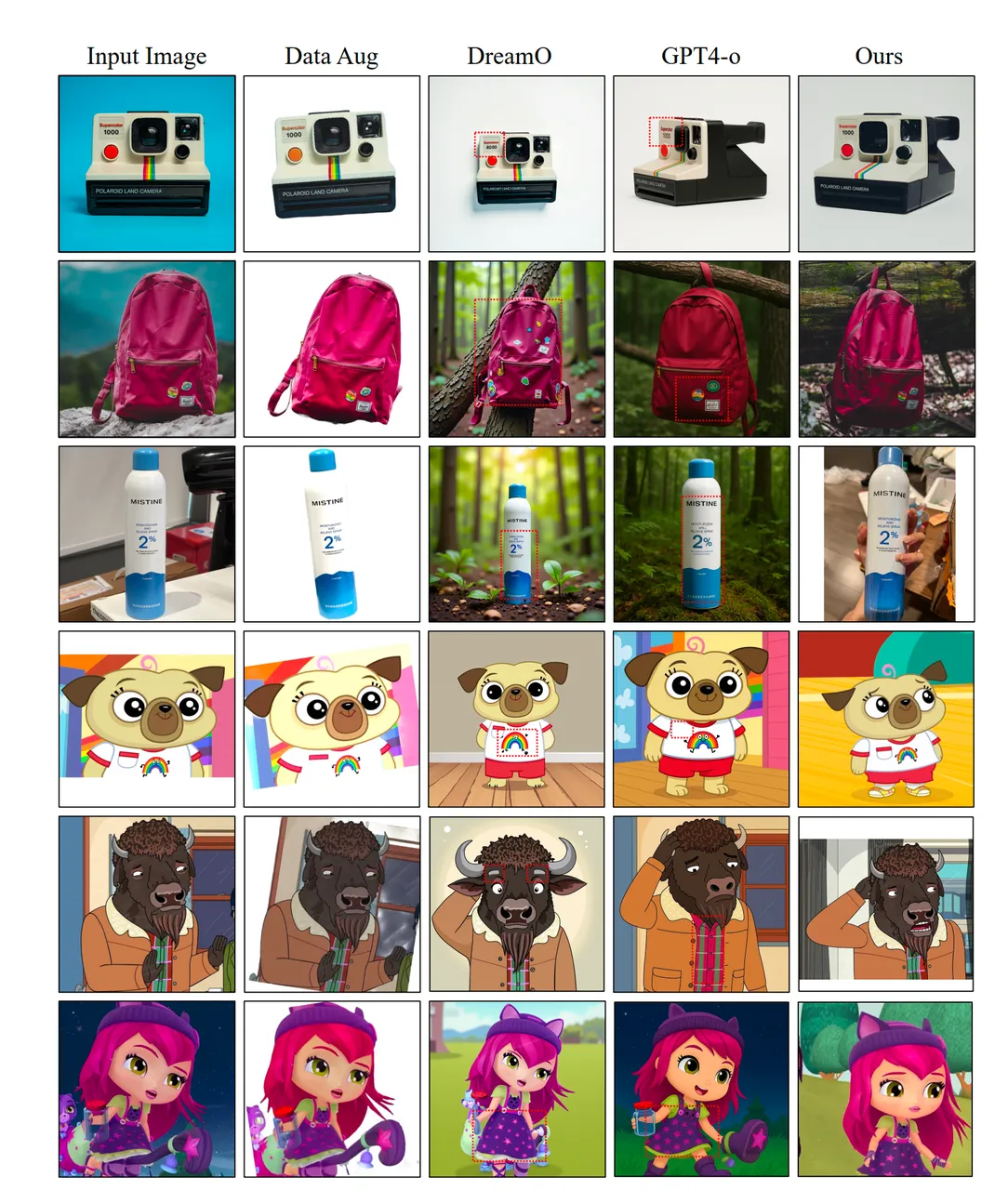
This helps avoid the “copy-paste” effect from in-pair training, where the model mixes the subject with the same scene. With real cross-pair data, the model learns the subject, not the background.
What the Team Learned From Training Datasets
They studied how training on different datasets affects results. A subject-centric detector tuned for the task helps get clean, input-aligned subjects.
A large retrieval system plus strong ID checks gives higher prompt alignment without losing identity quality. In short, better data pairing improves both what the video shows and how well it follows your words.
Installation & Setup
Follow these steps to run subject-to-video generation with Phantom-Wan models.
Clone the repo:
git clone https://github.com/Phantom-video/Phantom.git
cd Phantom
Install dependencies:
# Ensure torch >= 2.4.0
pip install -r requirements.txt
Model Download
First you need to download the 1.3B original model of Wan2.1, since our Phantom-Wan model relies on the Wan2.1 VAE and Text Encoder model. Download Wan2.1-1.3B using huggingface-cli:
pip install "huggingface_hub[cli]"
huggingface-cli download Wan-AI/Wan2.1-T2V-1.3B --local-dir ./Wan2.1-T2V-1.3B
Then download the Phantom-Wan-1.3B and Phantom-Wan-14B model:
huggingface-cli download bytedance-research/Phantom --local-dir ./Phantom-Wan-Models
Alternatively, you can manually download the required models and place them in the Phantom-Wan-Models folder.
Run Subject-to-Video Generation
Phantom-Wan-1.3B
- Single-GPU inference
python generate.py --task s2v-1.3B --size 832*480 --ckpt_dir ./Wan2.1-T2V-1.3B --phantom_ckpt ./Phantom-Wan-Models/Phantom-Wan-1.3B.pth --ref_image "examples/ref1.png,examples/ref2.png" --prompt "暖阳漫过草地,扎着双马尾、头戴绿色蝴蝶结、身穿浅绿色连衣裙的小女孩蹲在盛开的雏菊旁。她身旁一只棕白相间的狗狗吐着舌头,毛茸茸尾巴欢快摇晃。小女孩笑着举起黄红配色、带有蓝色按钮的玩具相机,将和狗狗的欢乐瞬间定格。" --base_seed 42
- Multi-GPU inference using FSDP + xDiT USP
pip install "xfuser>=0.4.1"
torchrun --nproc_per_node=8 generate.py --task s2v-1.3B --size 832*480 --ckpt_dir ./Wan2.1-T2V-1.3B --phantom_ckpt ./Phantom-Wan-Models/Phantom-Wan-1.3B.pth --ref_image "examples/ref3.png,examples/ref4.png" --dit_fsdp --t5_fsdp --ulysses_size 4 --ring_size 2 --prompt "夕阳下,一位有着小麦色肌肤、留着乌黑长发的女人穿上有着大朵立体花朵装饰、肩袖处带有飘逸纱带的红色纱裙,漫步在金色的海滩上,海风轻拂她的长发,画面唯美动人。" --base_seed 42
💡Note:
-
Changing --ref_image can achieve single reference Subject-to-Video generation or multi-reference Subject-to-Video generation. The number of reference images should be within 4.
-
To achieve the best generation results, we recommend that you describe the content of the reference image as accurately as possible when writing --prompt. For example, "examples/ref1.png" can be described as "a toy camera in yellow and red with blue buttons".
-
When the generated video is unsatisfactory, the most straightforward solution is to try changing the --base_seed and modifying the description in the --prompt.
For more inference examples, please refer to "infer.sh". You will get the following generated results:
Phantom-Wan-14B
- Single-GPU inference
python generate.py --task s2v-14B --size 832*480 --frame_num 121 --sample_fps 24 --ckpt_dir ./Wan2.1-T2V-1.3B --phantom_ckpt ./Phantom-Wan-Models --ref_image "examples/ref12.png,examples/ref13.png" --prompt "扎着双丸子头,身着红黑配色并带有火焰纹饰服饰,颈戴金项圈、臂缠金护腕的哪吒,和有着一头淡蓝色头发,额间有蓝色印记,身着一袭白色长袍的敖丙,并肩坐在教室的座位上,他们专注地讨论着书本内容。背景为柔和的灯光和窗外微风拂过的树叶,营造出安静又充满活力的学习氛围。"
- Multi-GPU inference using FSDP + xDiT USP
pip install "xfuser>=0.4.1"
torchrun --nproc_per_node=8 generate.py --task s2v-14B --size 832*480 --frame_num 121 --sample_fps 24 --ckpt_dir ./Wan2.1-T2V-1.3B --phantom_ckpt ./Phantom-Wan-Models --ref_image "examples/ref14.png,examples/ref15.png,examples/ref16.png" --dit_fsdp --t5_fsdp --ulysses_size 8 --ring_size 1 --prompt "一位戴着黄色帽子、身穿黄色上衣配棕色背带的卡通老爷爷,在装饰有粉色和蓝色桌椅、悬挂着彩色吊灯且摆满彩色圆球装饰的清新卡通风格咖啡馆里,端起一只蓝色且冒着热气的咖啡杯,画面风格卡通、清新。"
💡Note:
-
The currently released Phantom-Wan-14B model was trained on 480P data but can also be applied to generating videos at 720P and higher resolutions, though the results may be less stable. We plan to release a version further trained on 720P data in the future.
-
The Phantom-Wan-14B model was trained on 24fps data, but it can also generate 16fps videos, similar to the native Wan2.1. However, the quality may experience a slight decline.
-
It is recommended to generate horizontal videos, as they tend to produce more stable results compared to vertical videos.
For more inference examples, please refer to "infer.sh". You will get the following generated results:
The GIF videos are compressed.
Phantom-Data: Subject-Consistent Video Generation Use Cases
- Ads and brand videos: Keep a mascot or product the same across many scenes.
- Film pre-s: Test ideas with the same actors across different settings quickly.
- Education and training: Keep a tutor or character steady while showing new scenes or steps.
- Social content and avatars: Create short videos where your character stays the same, even as you change the scene or mood.
If you want context on the team behind this work, see our short profile on Bytedance.
Performance & Showcases
Showcase 1 — We introduce Phantom-Data, the first general-purpose large-scale cross-pair dataset aimed at addressing the notorious copy-paste problem in subject-to
Showcase 2 — Dataset Overview
The Technology Behind It
Phantom is built on text-image-video triplet data. The team redesigned how text and image signals are injected into the video model so that identity is preserved and the prompt is followed.
The dataset is the key. By pulling pairs of the same subject from different contexts and then checking identity with strong filters, the model learns the subject separate from the scene.
FAQ
What problem does Phantom-Data solve?
It fixes the “copy-paste” effect. Models trained on in-pair data can stick to the same background and ignore the prompt. Cross-pair data teaches the model to keep the subject and follow the prompt at the same time.
How many reference images can I use?
You can use up to four reference images. This works for both the 1.3B and 14B setups. Change --ref_image to list them, separated by commas.
Do I need very strong hardware?
You can run single-GPU with the 1.3B setup. For bigger runs or 14B, multi-GPU with FSDP is supported. Commands for both cases are shown above.
Can I make vertical videos?
You can, but horizontal videos are more stable with the current release. The team also notes 24fps training but support for 16fps output. Quality may change a bit at different sizes and fps.
What makes this dataset special?
It is cross-pair and very large. It was built from many sources and then verified to keep identity across different places and contexts. This makes prompt following better without losing who the subject is.
Image source: Phantom-Data: Revolutionizing Subject-Consistent Video Generation