How MMPhysVideo Enhances Physical Plausibility in Video Generation

What is How MMPhysVideo Enhances Physical Plausibility in Video Generation
MMPhysVideo is a research project that helps AI made videos follow real world physics better. It aims to make things like water flow, fire, falling, and mixing look right and move in a way that makes sense.
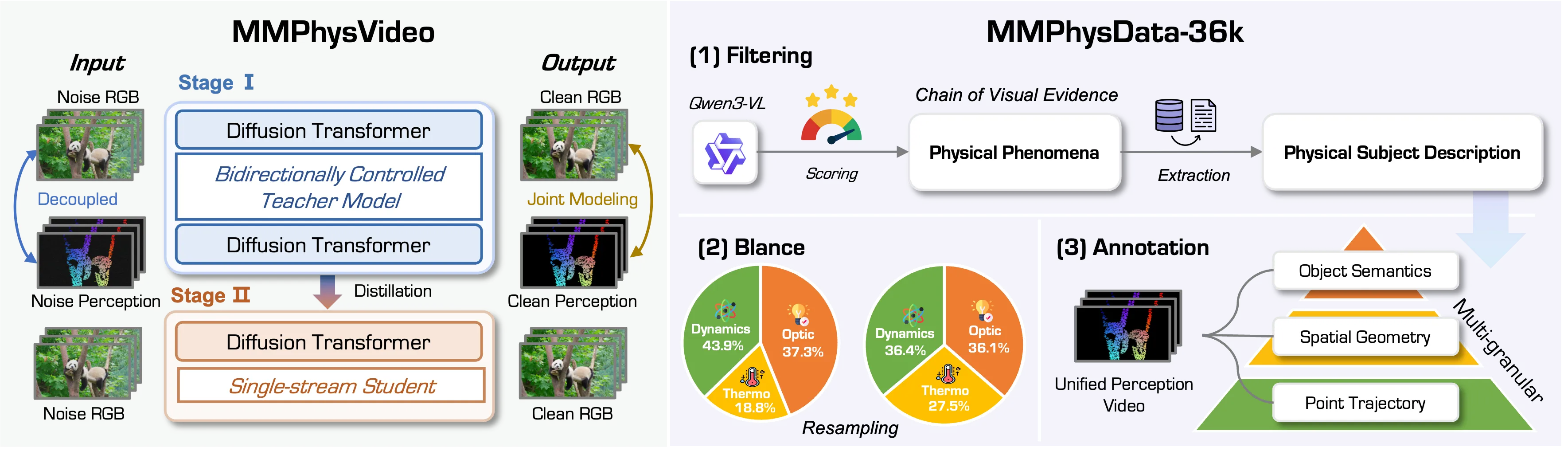
It does this by teaching a video model to understand not only pixels but also meaning, shape, and motion in space and time. The team designed a teacher student setup and a data pipeline to support this goal.
How MMPhysVideo Enhances Physical Plausibility in Video Generation Overview
Here is a quick overview of the project.
| Item | Details | | Project Name | MMPhysVideo | | Type | Research framework for video generation | | Goal | Make AI videos follow real world physics without extra run time cost | | Key Idea | Joint multimodal modeling of pixels, meaning, geometry, and motion in one pseudo RGB space | | Training Setup | Bidirectionally Controlled Teacher and a distilled Student | | Data Pipeline | MMPhysPipe with a chain of evidence process guided by a vision language model | | Status | Under review | | Code | Coming soon | | Dataset | Coming soon | | Baselines shown | CogVideoX 2B and 5B, VideoREPA, Wan2.1 1.3B | | Output | Higher physical plausibility and strong image and motion quality across tasks |
If you are new to this topic, start with our simple guide to text driven video in this text to video primer.
How MMPhysVideo Enhances Physical Plausibility in Video Generation Key Features
Joint multimodal modeling in a pseudo RGB space The model converts meaning, 3D shape hints, and motion over time into a form that looks like RGB channels. This lets a video diffusion model learn about objects, their shape, and how they move together. The goal is to help the model respect mass, flow, and other basic rules.
Bidirectionally Controlled Teacher Training uses a teacher with two branches. One branch handles normal RGB video, and the other handles perception cues like meaning, shape, and motion. Two zero initialized control links let the model slowly learn pixel level agreement between branches without cross talk.
Fast Student through distillation The team distills the teacher into a single branch student model. They align the learned representations so the student keeps the physics knowledge. The student runs with no extra cost at inference time.
MMPhysPipe for data curation The pipeline uses a vision language model with a chain of evidence rule to find the right physical subject in a clip. Expert models then extract meaning, geometry, and motion in different levels of detail. This creates a dataset that is rich in physics cues.
Better physics with no extra run cost The approach aims to improve both the look and the motion of the video while keeping the same run time. Tests across many prompts and baselines show state of the art results in physics heavy scenes.
How MMPhysVideo Enhances Physical Plausibility in Video Generation Use Cases
Fluids and mixing Prompts like honey in milk or oil in a pan need correct thickness, flow, and spread. MMPhysVideo helps the model show these effects in a stable way.
Fire, smoke, and steam When water hits fire, we expect steam and flame changes. The method helps produce believable interactions and timing.
Falling, bouncing, and collisions From an apple splash to a log in a river, the project aims to match motion, speed, and impact in a natural way. The results look consistent across frames.
Everyday actions Cases like lotion on skin or a knife cutting bread need correct contact, pressure, and residue. The model learns cues that help these fine details.
Longer prompts and context For readers who want to learn about long range prompts and context memory in video, see our notes on long context video methods.
How it Works
MMPhysVideo teaches a video diffusion model to learn pixels and extra cues together. It recasts meaning, geometry, and space time motion into a pseudo RGB format and runs them in parallel with normal RGB.
A teacher model keeps two branches apart and uses two control links that start at zero to reduce mixing errors. Later, the team distills the learned physics into a single branch student, so run time stays the same.
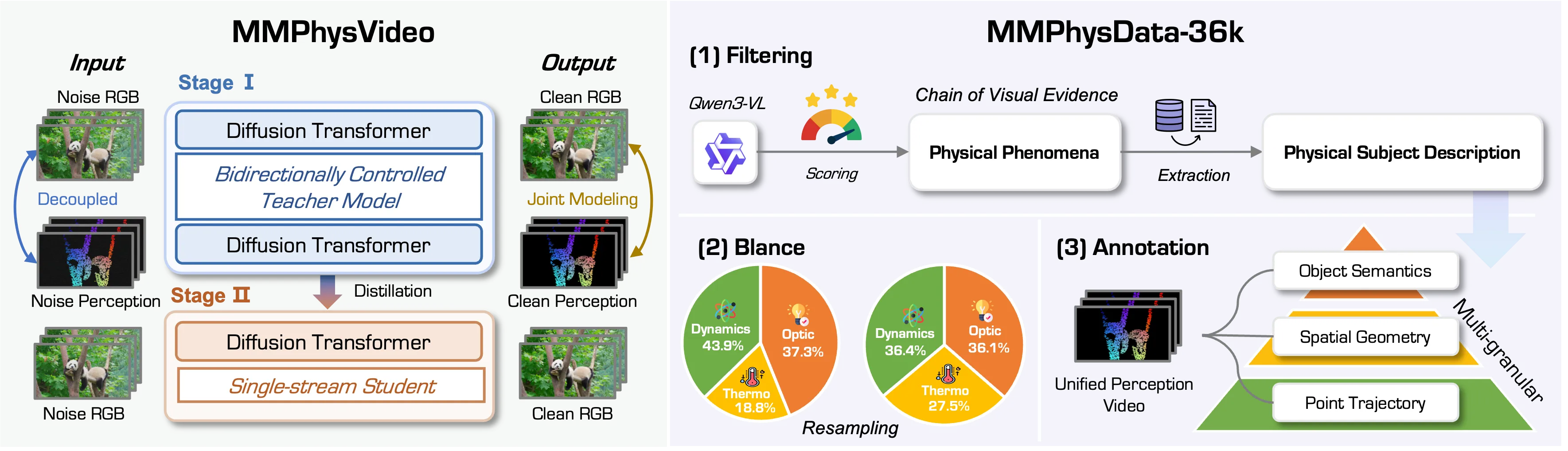
The MMPhysPipe data process finds the right physical subject with a chain of evidence. It then extracts many levels of meaning, shape, and motion, so the training set is rich and focused.
For a look at another strong generator line, see our take on Goku video generation progress.
Performance & Showcases
Showcase 1 — Honey diffusing into warm milk.
Showcase 2 — Honey diffusing into warm milk.
Showcase 3 — Honey diffusing into warm milk.
Showcase 4 — A hose sprays water onto a burning pile of tires, extinguishing the flames and creating steam.
Showcase 5 — A hose sprays water onto a burning pile of tires, extinguishing the flames and creating steam.
Showcase 6 — A hose sprays water onto a burning pile of tires, extinguishing the flames and creating steam.
The Technology Behind It
Teacher with two branches The RGB branch focuses on pixel quality and consistency across frames. The perception branch reads meaning, shape, and motion cues that point to how things should move.
Controlled learning Two links connect the branches with control that starts at zero. This slow start lets the teacher learn tight pixel wise rules without chaos between branches.
Student for real use The teacher’s knowledge is moved into a student that has one branch. This keeps run time simple and fast while holding on to the physics skills.
Getting Started and Project Status
Code and dataset are marked as coming soon on the project page. The paper is under review. When the team releases code, expect setup steps for environment, model weights, and inference scripts on the same page.
If you want a broad view of how text prompts turn into short clips, here is a helpful intro to text to video systems.
Practical Tips for Better Prompts
Be clear on the action and the subject. Write the material type when it matters, like honey, oil, rubber, or steam.
Add simple context that matters for physics, like warm milk, wet road, or hot pan. Keep prompts short and focused to avoid conflict cues.
If results look off, change one thing at a time. Adjust the verb, the material, or the setting, then test again.
FAQ
What does joint multimodal modeling mean here
It means the model learns from pixels and extra cues at the same time. These cues include meaning, shape hints, and motion across frames. They are packed into a form that looks like RGB so the model can learn them well.
Will it slow down video generation during inference
No. The teacher is only for training. The final student runs with no extra cost at inference time.
Can it help with tricky scenes like water on fire or heavy rain on a car
Yes. The project shows gains on many prompts with water, fire, liquids, and wet roads. The goal is to match how these things behave in the real world.
What datasets does it use
The team builds a dataset with MMPhysPipe. A vision language model finds the subject and expert tools extract meaning, shape, and motion.
When will the code be available
The page says code and dataset are coming soon. Keep an eye on the project site for updates.
Image source: How MMPhysVideo Enhances Physical Plausibility in Video Generation