X-Streamer: The Future of End-to-End Multimodal Human World Modeling
What is X-Streamer: The Future of End-to-End Multimodal Human World Modeling
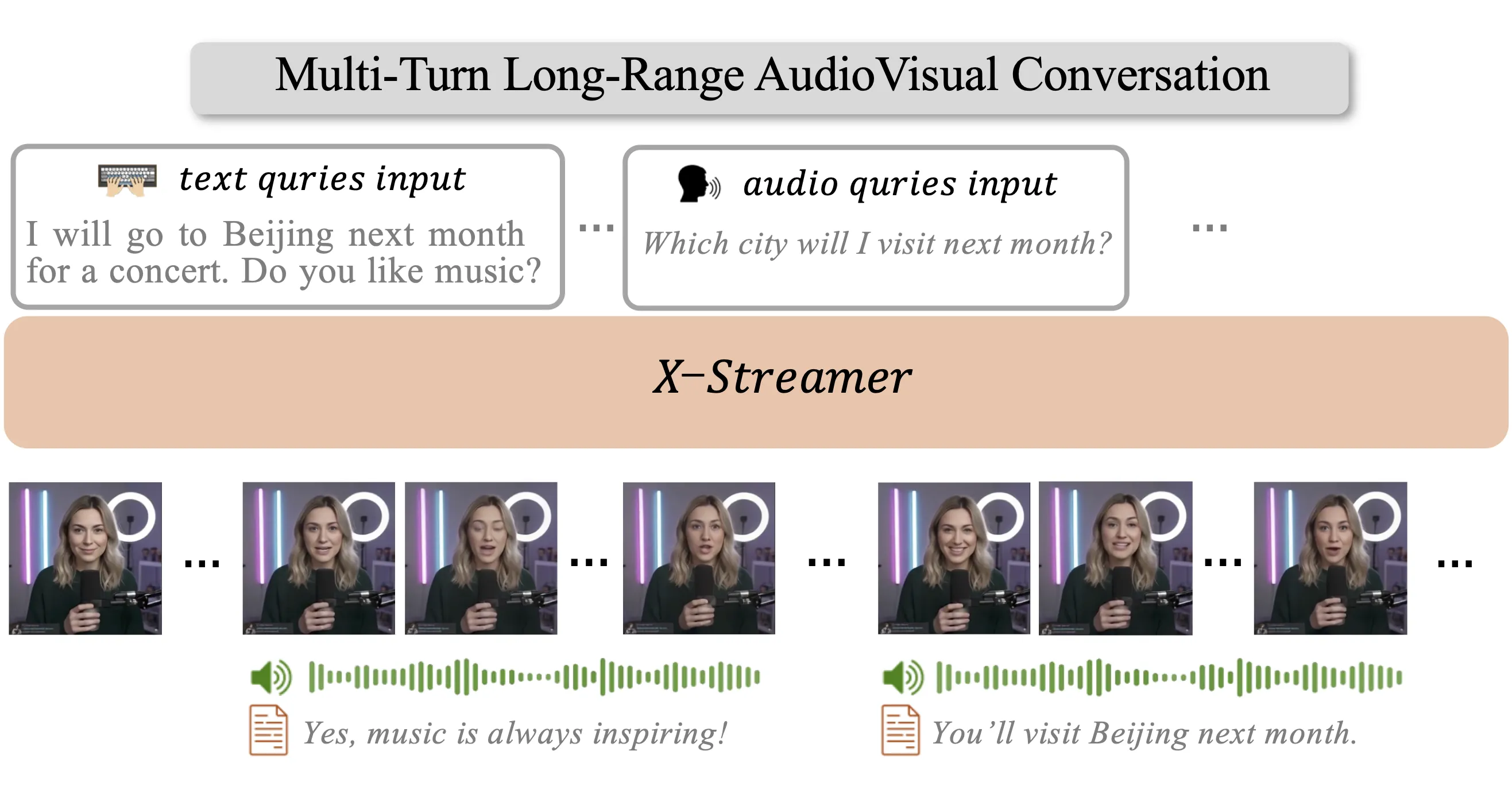
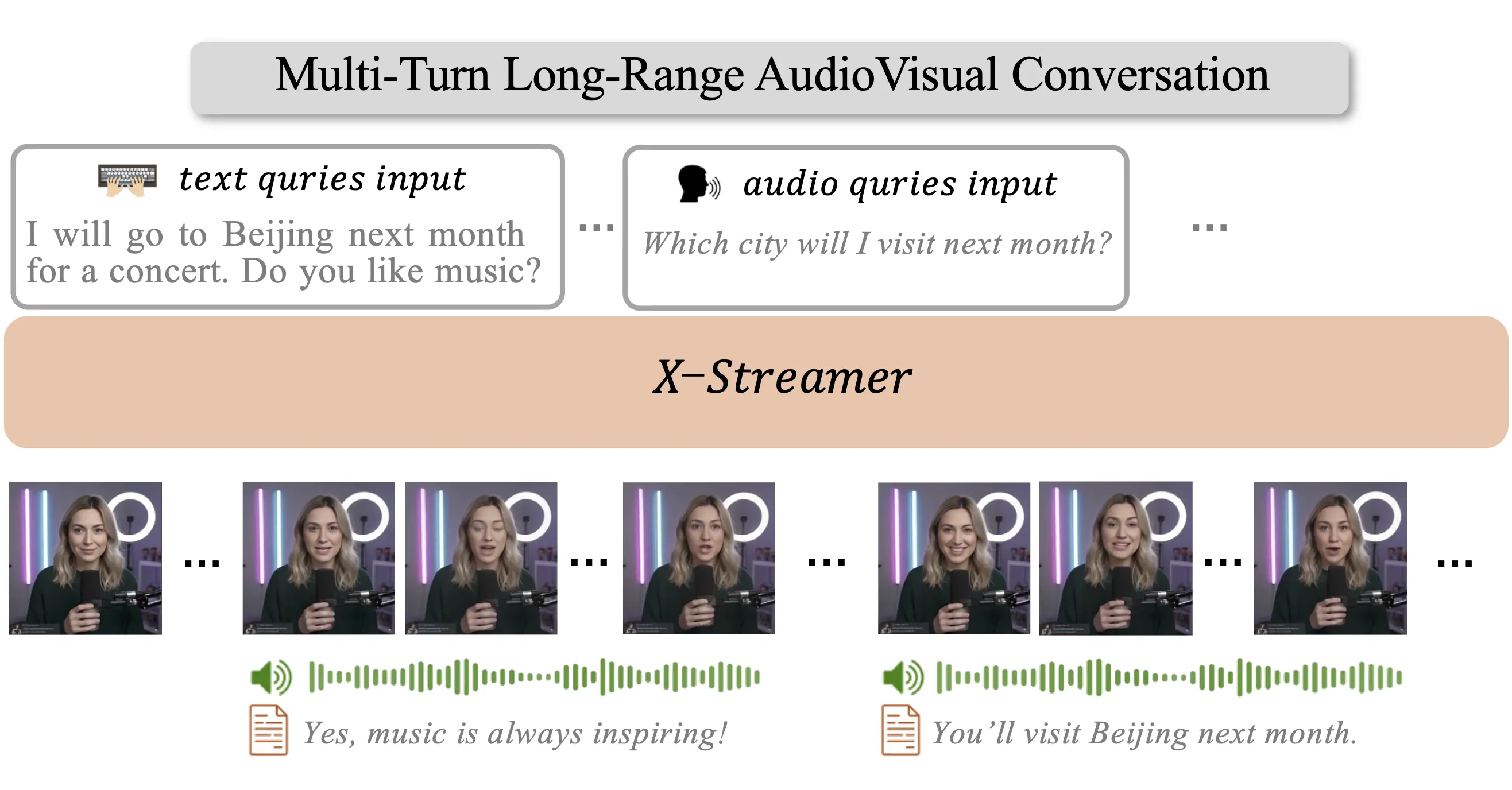
X-Streamer is a research project that turns a single portrait into a smart digital human you can talk to through text, voice, and video. It answers in real time and can keep a long chat going, across many turns.
It comes from the ByteDance Intelligent Creation team and focuses on one simple idea: one system to talk, listen, and show. For background on related work from the same group, see our broader look at ByteDance projects.
X-Streamer: The Future of End-to-End Multimodal Human World Modeling Overview
X-Streamer aims to model “human world” behavior end to end. In plain words, it can understand text and audio you give it, and reply back with text, speech, and video as one system. The project page shows demos of long chats, voice replies, and a digital face that talks back.
Project Overview
| Item | Details |
|---|---|
| Type | End-to-end multimodal human world modeling framework |
| Goal | Build an “infinitely streamable” digital human from one single portrait |
| Creator | ByteDance Intelligent Creation |
| Inputs | Text, speech, and video |
| Outputs | Text, speech, and video (real-time, multi-turn) |
| Conversation Length | Up to 8K tokens of context for longer chats and memory |
| Key Strengths | One system for all modes, real-time response, long-form dialog |
| Website | https://byteaigc.github.io/X-Streamer/ |
| Demos | Multiple videos showing interaction and long context |
| Code Release | Not stated on the project page at the time of writing |
X-Streamer: The Future of End-to-End Multimodal Human World Modeling Key Features
- One photo to start: It builds a digital human from a single portrait and can keep talking for as long as you chat.
- One brain for many modes: The same system handles text, voice, and video together, so it can speak and show at the same time.
- Real-time talk: It replies quickly and keeps the flow of the chat.
- Long memory: It can hold up to 8K tokens of your chat, which helps with longer talks and follow-ups.
- Multi-turn skill: It follows context across many rounds, not just one-off answers.
- Streamable output: It can keep the video and voice going over time, not just short clips.
If you are curious about turning portraits into avatars, see our short guide on portrait-based avatars from the same ecosystem.
X-Streamer: The Future of End-to-End Multimodal Human World Modeling Use Cases
- Virtual host or presenter: Run live talks, Q&A, or training with a digital human face and voice.
- Customer help or sales: Keep a natural chat across text and voice, with a face on screen.
- Education: Build a friendly tutor that remembers past steps in a lesson.
- Content creation: Make face-to-camera explainers, news briefs, or product demos.
- Accessibility: Offer voice and text modes together for flexible access.
Read More: motion synthesis work related to digital humans.
How It Works
Give the system a single portrait as the base. Then you chat by typing or talking, and it replies with text, voice, and a talking face video. It keeps track of the chat with up to 8K tokens, so it can answer follow-ups and keep the thread.
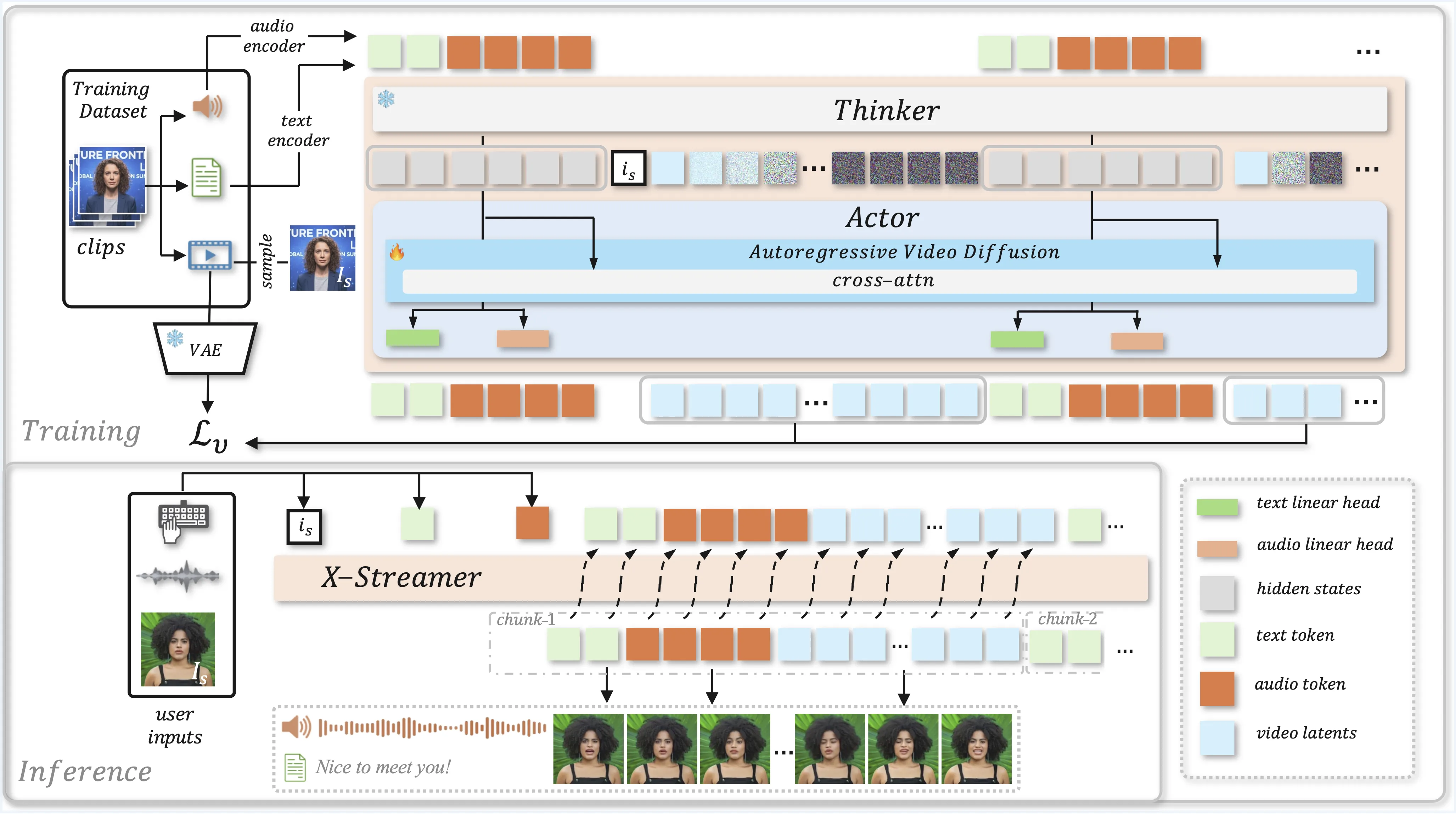
The same core model handles all parts. That means less switching between tools and more natural back-and-forth. It is set up to keep streaming, so longer talks feel steady.
The Technology Behind It
“Multimodal” means the model works with words, sound, and video in one place. The model builds a shared view of your message across these forms. Then it picks the next best reply and pushes out text, sound, and frames in sync.
The long context window, up to 8K tokens, helps the model recall what you said before. This gives better answers across many turns. The project shows how a single setup can talk and show at the same time.
Performance & Showcases
Showcase 1 — ByteDance Intelligent Creation preview ByteDance presents the overall vision and what the team set out to build. ByteDance Intelligent Creation
Showcase 2 — Infinite streamable generation demo This clip highlights how the digital human can keep going without a hard stop. Infinite Streamable Generation
Showcase 3 — Long chats with context up to 8K tokens This example shows longer talks and better memory across turns. X-Streamer accommodates up to 8K tokens of conversational context, facilitating advanced reasoning and long-term memory throughout multi-turn interact
Showcase 4 — Another multi-turn example with long memory Here you see more cases of deep context over many messages. X-Streamer accommodates up to 8K tokens of conversational context, facilitating advanced reasoning and long-term memory throughout multi-turn interact
Showcase 5 — More examples, different prompts This set gives a feel for range and style across various tasks. More Examples
Showcase 6 — More examples, more settings See more prompts and replies to understand scope. More Examples
Getting Started
- Visit the project page: https://byteaigc.github.io/X-Streamer/
- Watch the demo videos to see text, voice, and video in action.
- Check back on the page for any future updates on code or models.
FAQ
Who built X-Streamer?
It was built by the ByteDance Intelligent Creation team. The project page lists the team members and shares demos.
What makes X-Streamer special?
It runs text, speech, and video in one system and keeps long chats going. It also starts from just one portrait, which makes setup simple.
Can it talk in real time?
Yes, the demos show real-time replies with voice and a talking face. It also handles multi-turn chats.
How long a chat can it handle?
It supports up to 8K tokens of context. This helps with longer talks and better memory across turns.
Is there code I can download?
The project page does not show public code at the time of writing. You can watch the demos and follow the page for updates.
Image source: X-Streamer: The Future of End-to-End Multimodal Human World Modeling