GigaTok: Scaling Visual Tokenizers to 3 Billion Parameters for the Future of Image Generation
What is GigaTok: Scaling Tokenizers to 3 Billion Parameters for the Future of Image Generation
GigaTok is a research project that turns images into short “tokens” so a text-style model can learn to make new pictures. It pushes model size up to about 3 billion parameters while keeping training stable and keeping picture quality strong.
It also fixes a long-time tradeoff: better pixel copy often hurts picture creation later. GigaTok adds smart training rules so models can both copy well and create well.
GigaTok: Scaling Tokenizers to 3 Billion Parameters for the Future of Image Generation Overview
Here is a quick look at what this project offers.
| Type | Open-source research code and models |
|---|---|
| Goal | Scale image tokenizers up to ~3B parameters and make them work well for later picture generation |
| Key ideas | Focus on decoder size first, 1D design scales better than 2D, extra loss to keep training stable, “semantic regularization” to keep token meaning steady |
| Model sizes | From ~136M up to ~2.9B parameters |
| Image size | 256×256 |
| What you can do | Reconstruct images, run class-conditional generation, run linear probing tests |
| What you get | Ready configs, checkpoints, and scripts for training, testing, and sampling |
| Best for | Teams building AR (autoregressive) image makers and researchers studying tokenizers |
| Hardware note | Needs CUDA 12.1 and a modern GPU setup |
If you follow the broader AI scene, see our short industry notes here: Bytedance.
GigaTok: Scaling Tokenizers to 3 Billion Parameters for the Future of Image Generation Key Features
- Scales to ~3B parameters while keeping training stable with an extra entropy loss.
- Uses “semantic regularization” so tokens keep stable meaning across similar images.
- 1D design shows stronger growth than 2D under the same setup.
- Decoder-first growth helps downstream picture generation more than encoder-first growth.
- Full set of scripts for reconstruction, class-conditional sampling, and probing tests.
GigaTok: Scaling Tokenizers to 3 Billion Parameters for the Future of Image Generation Use Cases
- Build better image generators that run in an AR (autoregressive) style.
- Study how token size and shape affect both copying and creating pictures.
- Compare 1D and 2D designs under the same training rules.
- Test class-conditional image generation on ImageNet-like labels.
If you are also curious about moving pictures, check our friendly explainer on video tools: Goku Video Generation.
How GigaTok Works (Simple View)
GigaTok turns an image into a short list of tokens, much like words in a sentence. A GPT-like model then reads those tokens and learns how to make new ones that become new images.
The project shows how to grow model size, keep training steady, and keep the tokens meaningful. This helps both image copy (reconstruction) and later picture creation.
Why Scaling Is Hard—and What GigaTok Changes
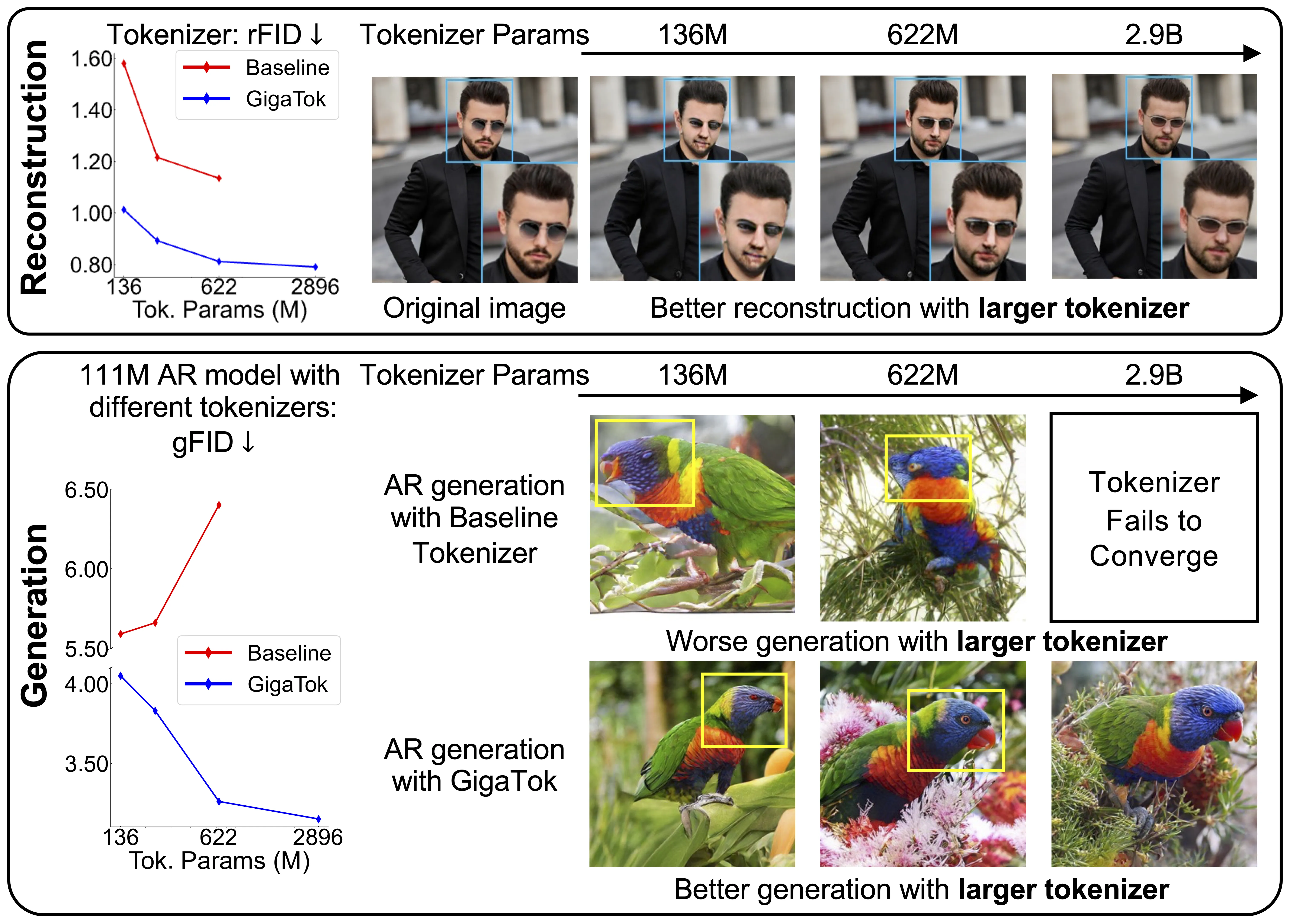
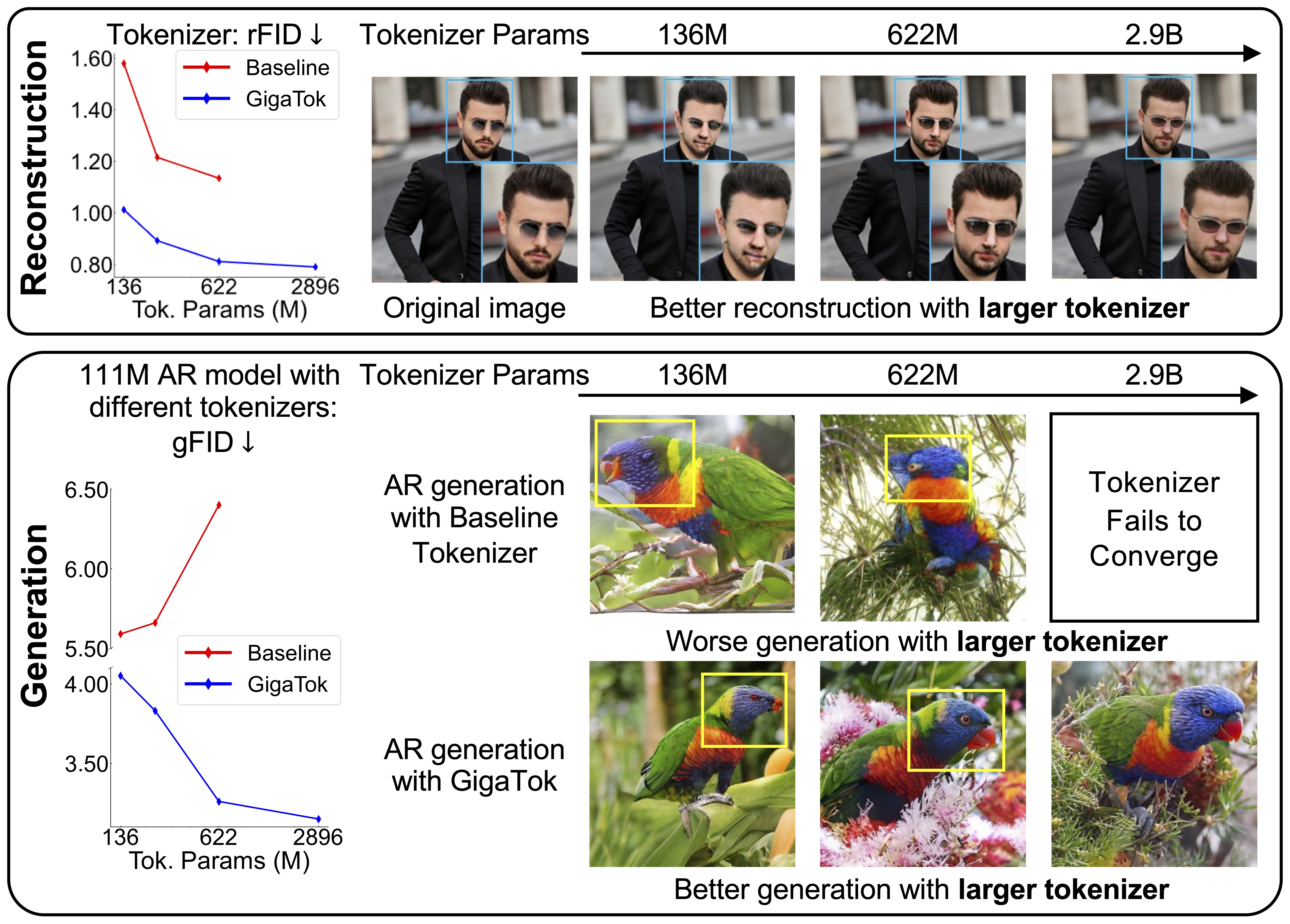
Bigger tokenizers can copy pixels better but can confuse the later generator. The reason is the hidden space becomes too complex, so the generator struggles.
GigaTok lowers this hidden complexity with simple but effective training rules. This brings gains in both copy and creation.
Smart Training Tricks That Make It Work
Entropy loss keeps big models from collapsing or becoming unstable during training. “Semantic regularization” keeps token meaning steady within and across similar images.
These tricks allow training up to ~2.9B+ and keep improvements steady over time.
1D vs 2D Designs: Which Scales Better?
Under the same setup, 1D designs show stronger growth for copying and for features used by downstream models. For generation, the 1D curve improves faster too.
If you must pick where to spend your compute, make the decoder bigger first. It brings more gain to the downstream generator than only growing the encoder.
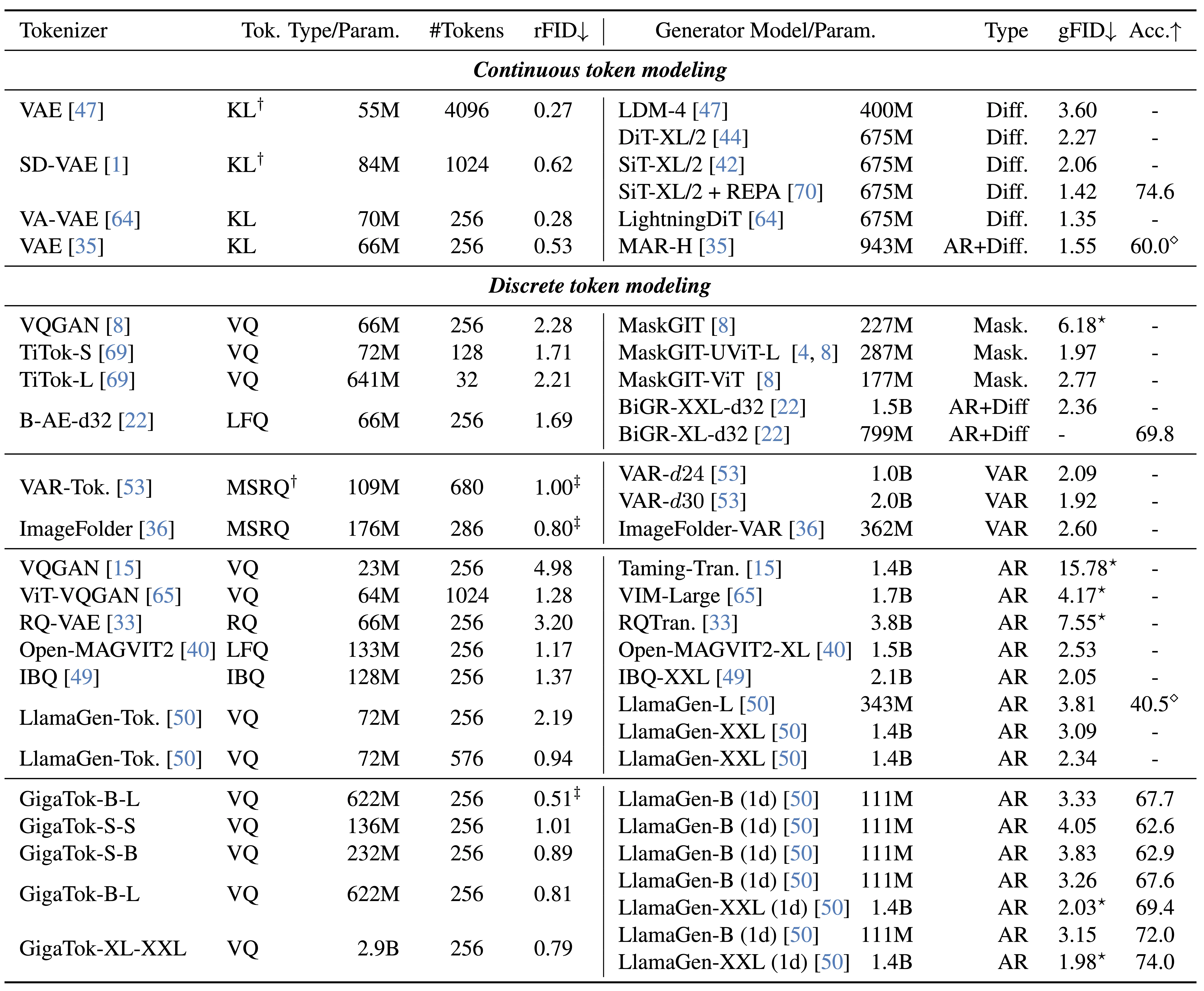
Main Results at a Glance
On ImageNet 256×256, GigaTok reports strong numbers for both copy quality and downstream generation. It also shows steady growth as model size increases.
You can also run class-conditional sampling and see the quality by yourself with the scripts below.
Read More: Omnihuman 1.Com
Performance & Showcases
The team reports strong reconstruction quality with lower rFID and better generation gFID trends as model size grows. The balance holds thanks to the training rules mentioned above.
You can reproduce example reconstructions and class-conditional samples using the “Reconstruction” and “Sampling” scripts in the next section.
Installation & Setup (Exact Steps from the Repo)
Follow these steps to set up your environment and run the provided scripts.
Environment Setup
# A working CUDA version: 12.1
# Correspond to TORCH_RUN_PATH in set_env_vars.sh
conda create -n gigatok python=3.9
conda activate gigatok
# Install required packages using the provided script
bash env_install.sh
Download Checkpoints
All tokenizers target 256×256 images. Models are also available on Hugging Face. Larger AR model checkpoints are provided in the repo.
Reconstruct Images (Tokenizer Reconstruction)
This script rebuilds images from tokens so you can see reconstruction quality.
- Set Environment Variables Modify set_env_vars.sh based on its comments. For this task, set PROJECT_ROOT and TORCH_RUN_PATH. Then run:
# Define the required path/env related variables
. set_env_vars.sh
# Choose the tokenizer configuration
# For S-S Tokenizer (128M)
export TOK_CONFIG="configs/vq/VQ_SS256.yaml"
export VQ_CKPT=results/recheck/VQ_SS256_e100.pt
# Uncomment the following for S-B (232M)
# export TOK_CONFIG="configs/vq/VQ_SB256.yaml"
# export VQ_CKPT=results/recheck/VQ_SB256_e200.pt
# Uncomment the following for B-L (622M)
# export TOK_CONFIG="configs/vq/VQ_BL256.yaml"
# export VQ_CKPT=results/recheck/VQ_BL256_e200.pt
# Uncomment the following for B-L (dino disc) (622M)
# export TOK_CONFIG="configs/vq/VQ_BL256_dinodisc.yaml"
# export VQ_CKPT=results/ckpts/VQ_BL256_dino_disc.pt
# Uncomment the following for XL-XXL (2.9B)
# export TOK_CONFIG="configs/vq/VQ_XLXXL256.yaml"
# export VQ_CKPT=results/ckpts/VQ_XLXXL256_e300.pt
- Run the Qualitative Reconstruction Script
DATA_PATH=${PROJECT_ROOT}/tests/
# this is the output directory
SAMPLE_DIR=results/reconstructions/
gpus=1 \
PORT=11086 \
bash scripts/reconstruction.sh \
--quant-way=vq \
--data-path=${DATA_PATH} \
--image-size=256 \
--sample-dir=$SAMPLE_DIR \
--vq-ckpt=${VQ_CKPT} \
--model-config ${TOK_CONFIG} \
--qualitative \
--lpips \
--clear-cache
For step-by-step scoring (quantitative metrics), the repo has a Detailed_instructions page.
Generate Class-Conditional Images (AR Model Inference)
This script draws images by class IDs (ImageNet-style labels).
Qualitative Sampling
# Try these classes!
# [388]='giant panda, panda, panda bear, coon bear, Ailuropoda melanoleuca'
# [90]='lorikeet'
# [323]='monarch, monarch butterfly, milkweed butterfly, Danaus plexippus'
# [84]='peacock'
# [980]='volcano'
# [977]='sandbar, sand bar'
# [978]='seashore, coast, seacoast, sea-coast'
# [979]='valley, vale'
# [972]='cliff, drop, drop-off'
# [105]='koala, koala bear, kangaroo bear, native bear, Phascolarctos cinereus'
# [22]='bald eagle, American eagle, Haliaeetus leucocephalus'
. set_env_vars.sh
export TOK_CONFIG="configs/vq/VQ_XLXXL256.yaml"
export VQ_CKPT=results/ckpts/VQ_XLXXL256_e300.pt
export LM_CKPT=results/ckpts/GPT_B256_e300_VQ_XLXXL.pt
CFG=4.0
CFG_SCHEDULE="constant"
GPT_MODEL="GPT-B"
SAMPLE_DIR=results/gpt_eval/GPT_B256_e300_VQ_XLXXL
# Uncomment for testing GPT-XXL
# export LM_CKPT=results/ckpts/GPT_XXL256_e300_VQ_XLXXL.pt
# CFG=4.0
# CFG_SCHEDULE="constant"
# GPT_MODEL="GPT-XXL"
# SAMPLE_DIR=results/gpt_eval/GPT_XXL256_e300_VQ_XLXXL
# sample results:
bash scripts/sample_c2i_ization.sh \
--quant-way=vq \
--image-size=256 \
--sample-dir=$SAMPLE_DIR \
--vq-ckpt ${VQ_CKPT} \
--tok-config ${TOK_CONFIG} \
--gpt-model ${GPT_MODEL} \
--cfg-schedule ${CFG_SCHEDULE} \
--cfg-scale ${CFG} \
--gpt-ckpt ${LM_CKPT} \
--precision fp16 \
--class-idx "22,388,90,978" \
--per-proc-batch-size 8 \
--qual-num 40
For scoring and more setups, see Detailed_instructions in the repo.
Tips for Best Results
- Use CUDA 12.1 to match the scripts. Set TORCH_RUN_PATH in set_env_vars.sh.
- Start with smaller configs (S-S or S-B) to test your setup, then move up to XL-XXL.
- Keep an eye on GPU memory when running the ~2.9B setup.
FAQ
Do I need a very strong GPU?
You need a modern GPU and CUDA 12.1 to follow the scripts as given. Bigger models will need more memory, so start small if you are unsure.
Can I run this on CPU?
The repo targets GPU with CUDA. CPU-only runs are not covered by the provided scripts.
Where do I get the checkpoints?
The repo links to checkpoints for tokenizers and AR models. They are also on Hugging Face as noted in the docs.
What is “semantic regularization” in plain words?
It is a training rule that keeps token meaning steady for similar images. This helps the later generator learn faster and produce better results.
What is the difference between reconstruction and generation here?
Reconstruction means copying back the input image from tokens. Generation means making a new image from learned tokens, like by a class label.
Image source: GigaTok: Scaling Tokenizers to 3 Billion Parameters for the Future of Image Generation