Solving the Logic Gap: How Enigmata Scales LLM Reasoning with Synthetic Puzzles
What is Solving the Logic Gap: How Enigmata Scales LLM Reasoning with Synthetic Puzzles
Solving the Logic Gap: How Enigmata Scales LLM Reasoning with Synthetic Puzzles is a project that helps AI models learn logic by solving small, rule-based puzzles. It includes a huge set of auto-generated puzzles, tools to check answers, a fair test set, and a training recipe that teaches models to think step by step.

At its heart, Enigmata treats logic like a sport: practice with many clean puzzles, verify each answer right away, then raise the difficulty. This lets models grow from basic patterns to stronger, general thinking. For a short, friendly intro, check our quick note on the topic here: Enigmata explainer.
Solving the Logic Gap: How Enigmata Scales LLM Reasoning with Synthetic Puzzles Overview
Here’s a fast summary of the project.
| Item | Details |
|---|---|
| Type | Open-source dataset, benchmark, and training recipe for logic puzzles |
| Purpose | Build reliable step-by-step reasoning in language models using puzzles with auto-checking |
| Main Features | 36 tasks across 7 categories, infinite data via generators, rule-based verifiers, difficulty control, easy RL integration, strong evaluation |
| Dataset | Enigmata-Data on Hugging Face (synthetic, verifiable puzzles) |
| Tasks & Scope | 36 puzzle types, each with a generator and a verifier |
| Difficulty | Easy / Medium / Hard with fine control |
| Evaluation | Enigmata-Eval (4,758 puzzles), strict train–test split, automatic scoring |
| Training Approach | Two stages: Rejection Fine-tuning (RFT), then multi-task RL with verifiable rewards (VC-PPO) |
| Model Highlight | Qwen2.5-32B-Enigmata excels on Enigmata-Eval, ARC-AGI, ARC-AGI 2; carries over gains to AIME and GPQA Diamond |
| Project Site | Project homepage |
Read More: More on the team and background
Solving the Logic Gap: How Enigmata Scales LLM Reasoning with Synthetic Puzzles Key Features
- Infinite, clean training data: Each puzzle type comes with a generator that can create as many unique examples as you need.
- Trustworthy scoring: A built-in verifier checks answers with rules, so each step in training gets instant feedback.
- Precise difficulty control: You can pick Easy, Medium, or Hard and even balance the mix.
- Simple to plug into RL: Verifiers give clear rewards, which helps reinforcement learning move forward without manual grading.
- Wide coverage: 36 tasks across 7 puzzle groups (logic, arithmetic, crypto, search, spatial, and more).
- Fair testing: Enigmata-Eval offers a clean test set with strict split to avoid data leaks.
Meet a Few Puzzle Types
Binario
This is a grid of 0s and 1s. Each row and column has an equal number of 0s and 1s with no repeating triplets, and the final grid must be unique. It teaches pattern rules and local constraints.

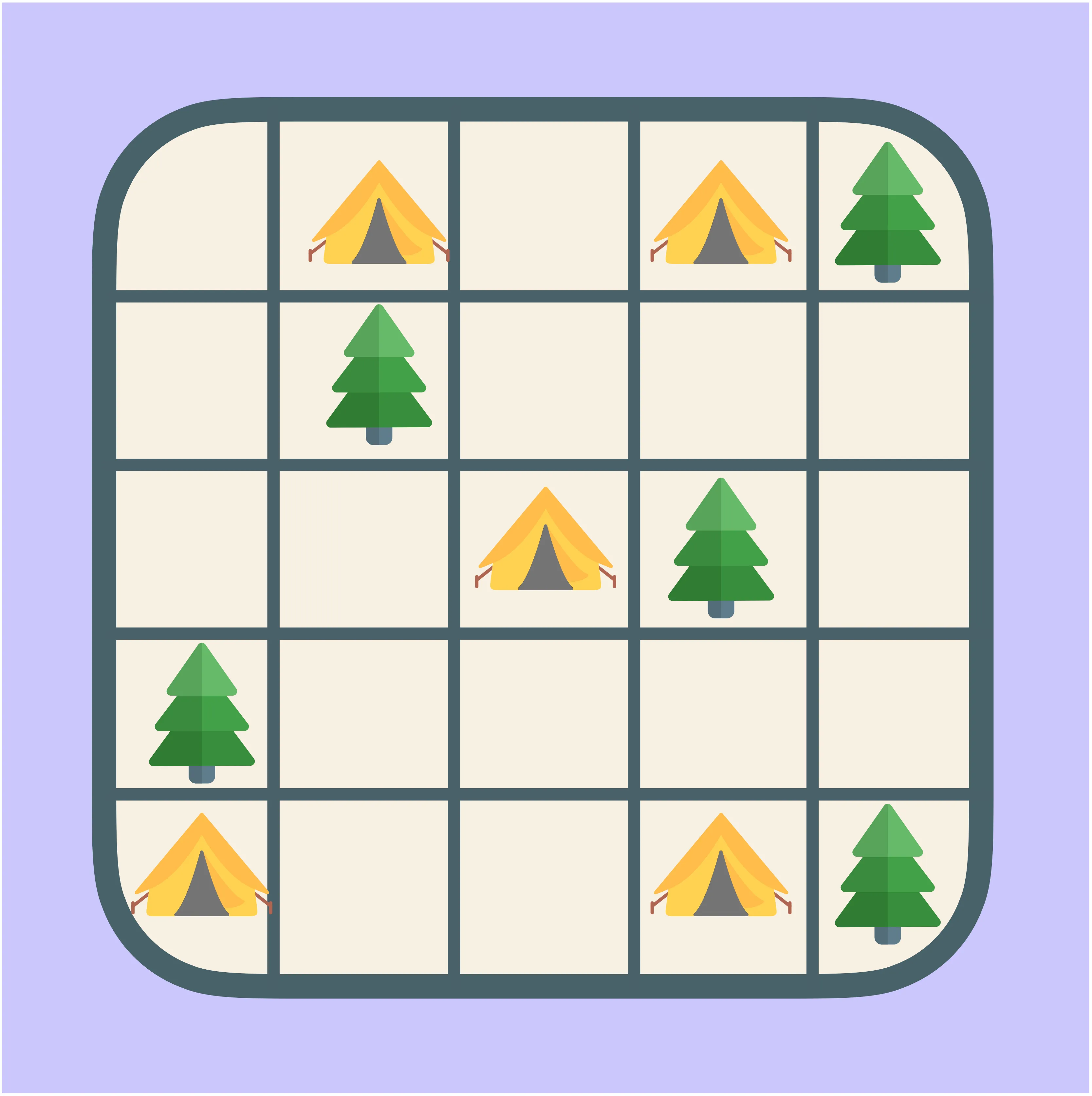
Campsite
You see trees and empty cells on a grid. Place “tents” so each tent touches exactly one tree, and tents do not touch each other. This builds skills in local matching and constraint tracking.
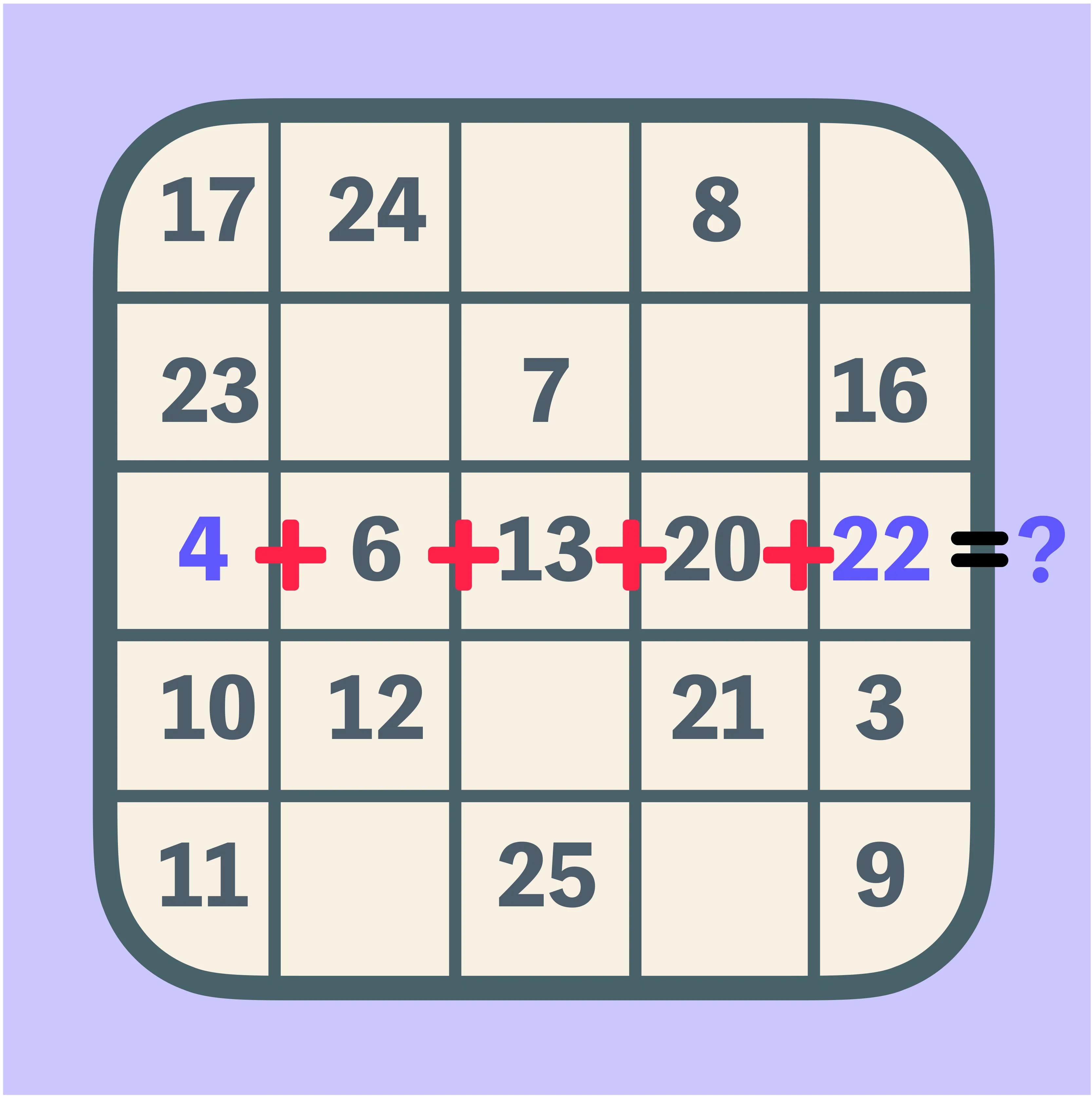
Magic Square
Fill a square so rows, columns, and both diagonals add up to the same total. This trains number reasoning with multiple constraints at once.
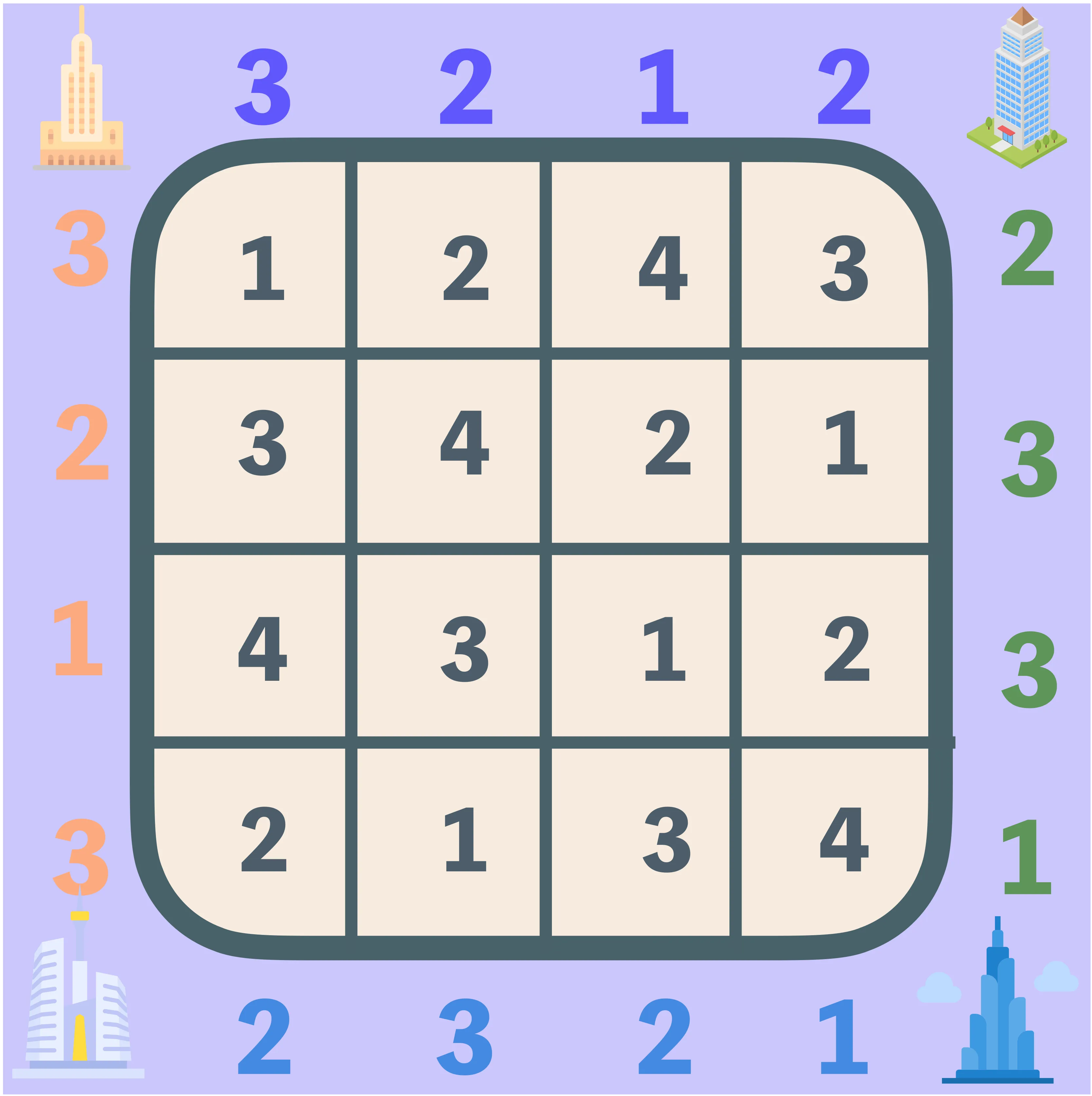
Skyscraper
Numbers around the border tell how many “buildings” you can see from that side. Place building heights in the grid so all rules are met and no numbers repeat in any row or column.
Read More: See more guides and roundups
Solving the Logic Gap: How Enigmata Scales LLM Reasoning with Synthetic Puzzles Use Cases
- Train a model to think step by step with clear, checkable feedback.
- Study how difficulty affects learning and plan simple or mixed “curricula.”
- Build and test new RL methods using automatic, rule-based rewards.
- Run fair comparisons between models on a clean, puzzle-based benchmark.
- Add puzzle data to big training runs to boost math and STEM tasks.
How It Works
Enigmata uses a generator–verifier pair for each task. The generator makes fresh puzzles with chosen difficulty, and the verifier checks if the answer is correct.
Training happens in two stages. First, Rejection Fine-tuning (RFT) teaches good solution patterns from high-quality answers to math and puzzle sets (including ARC-AGI). Second, multi-task reinforcement learning uses verifiers to give rewards, so the model learns to solve many puzzle types and generalizes better.
There is also multi-task mixing (puzzles plus math like AIME). This keeps balance across types and prevents the model from forgetting math skills while it gets better at logic.
The Technology Behind It
- Rejection Fine-tuning builds a base: the model sees many good solutions and learns safe, structured steps.
- RL with verifiable puzzles grows general skill: verifiers give instant, rule-based rewards (VC-PPO), so training can run on its own.
- Multi-task training blends sources: Enigmata, ARC-AGI, and AIME are mixed to improve transfer across tasks.
When scaled to larger models such as Seed1.5-Thinking, puzzle data from Enigmata also lifts scores on AIME and GPQA Diamond. This shows puzzle training can help far beyond puzzles.
Installation & Setup
Follow these exact commands to generate data and run evaluation.
Generate custom puzzle data
Use these commands to create training and test splits, and to check for data leaks.
# Generate training data for specific tasks
python3 generate_all_tasks.py \
--count 2000 \
--split train \
--output /your/training/data/path \
--tasks maze
# Generate evaluation data
python3 generate_all_tasks.py \
--count 1000 \
--split test \
--output /your/evaluation/data/path \
--tasks maze
# Ensure data integrity with leakage detection
python check_data_leakage.py \
--eval-root /your/evaluation/data/path \
--train-root /your/training/data/path \
--output-root /your/clean/evaluation/path \
--report /your/reports/data_leakage_report.csv
Pro Tip: Omit --tasks parameter to generate data for all 36 available tasks simultaneously.
Evaluate your model on Enigmata-Eval
Place your model’s predictions into the output column of result.parquet, then run:
# Run comprehensive evaluation
python test_eval.py --input result.parquet
The tool uses task-specific verifiers to grade each answer.
Performance & Showcases
The Qwen2.5-32B-Enigmata model scores very well on Enigmata-Eval and ARC-AGI. It is especially strong in Crypto, Arithmetic, and Logic, and holds its own in search, with more room to grow in spatial and sequential sets.
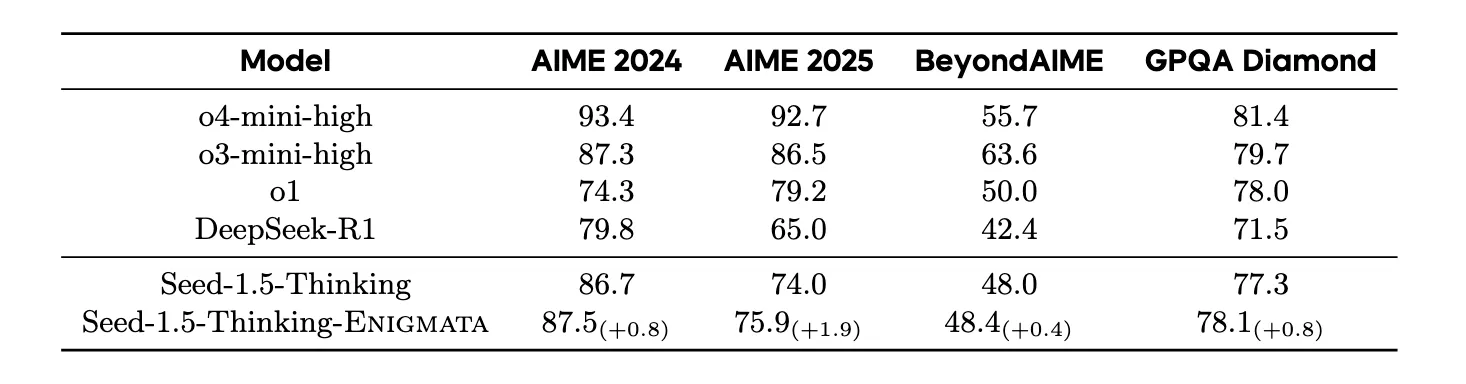
When training includes Enigmata-Data at larger scales (for example, Seed1.5-Thinking with 20B activated parameters and 200B total parameters), results on hard tests like AIME and GPQA Diamond also improve. This suggests puzzle training adds sturdy, general reasoning habits.
Step-by-Step: From Data to Results
-
Generate your dataset. Start small with one task (like maze), then increase the count and mix in more tasks as needed.
-
Train with two stages. Use RFT on high-quality solutions to set a base, then move to multi-task RL with verifiers for puzzle rewards.
-
Evaluate fairly. Use Enigmata-Eval and the provided tool to score your model across all tasks and difficulties.
Why This Matters
Good reasoning is more than getting the final answer. It is about following rules, tracking constraints, and showing why each step makes sense.
Puzzles give fast, clear feedback with no manual scoring. That makes them a great way to teach logic to language models.
FAQ
What makes Enigmata different from plain math datasets?
Enigmata focuses on puzzles with exact rules and auto-checking, so every answer can be verified right away. This gives clean rewards for RL and supports careful reasoning practice.
Can I control how hard the puzzles are?
Yes. Each generator comes with difficulty controls, so you can target Easy, Medium, or Hard and plan your training mix.
Is there a public model to try?
Yes. The team trained Qwen2.5-32B-Enigmata, which performs very well on Enigmata-Eval and ARC-AGI. It also shows gains on math and science tests like AIME and GPQA Diamond.
How do I know my test data is clean?
Use the leakage check command provided in the setup. It compares training and test roots and outputs a report so you can keep splits strict.
Does puzzle training help outside of puzzles?
The results suggest yes. When puzzle data is added to larger training runs, models often improve on hard math and STEM benchmarks too.
Image source: Solving the Logic Gap: How Enigmata Scales LLM Reasoning with Synthetic Puzzles