FML: Unified Vector Floorplan Generation via Markup Representation
What is FML: Unified Vector Floorplan Generation via Markup Representation
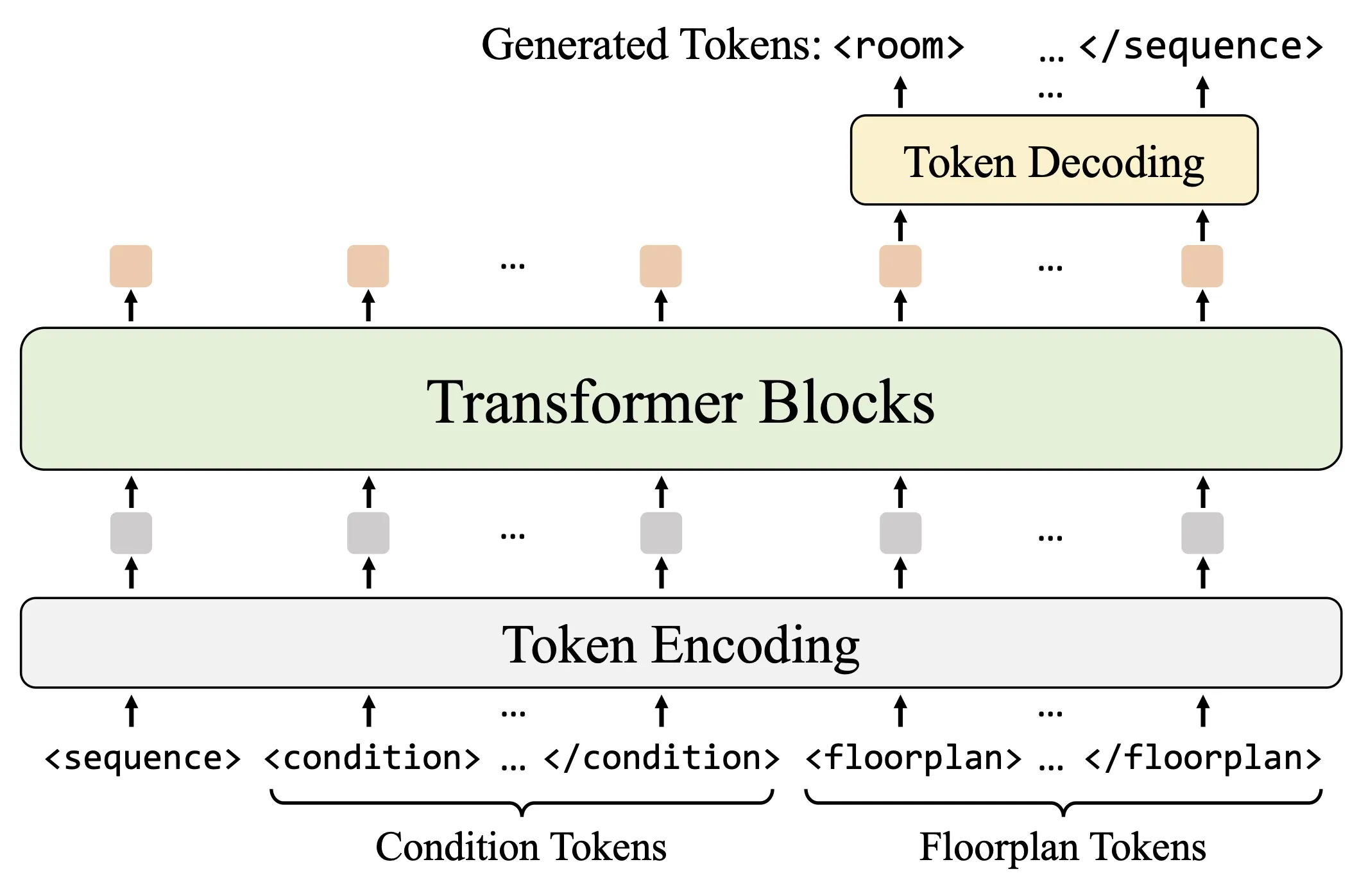
FML is a research project that turns the task of drawing building floorplans into simple text like steps. It uses a markup language so a model can predict one token at a time and build the full plan from start to finish. This makes it easy to handle many kinds of inputs and room counts without fixing the number of rooms ahead of time.
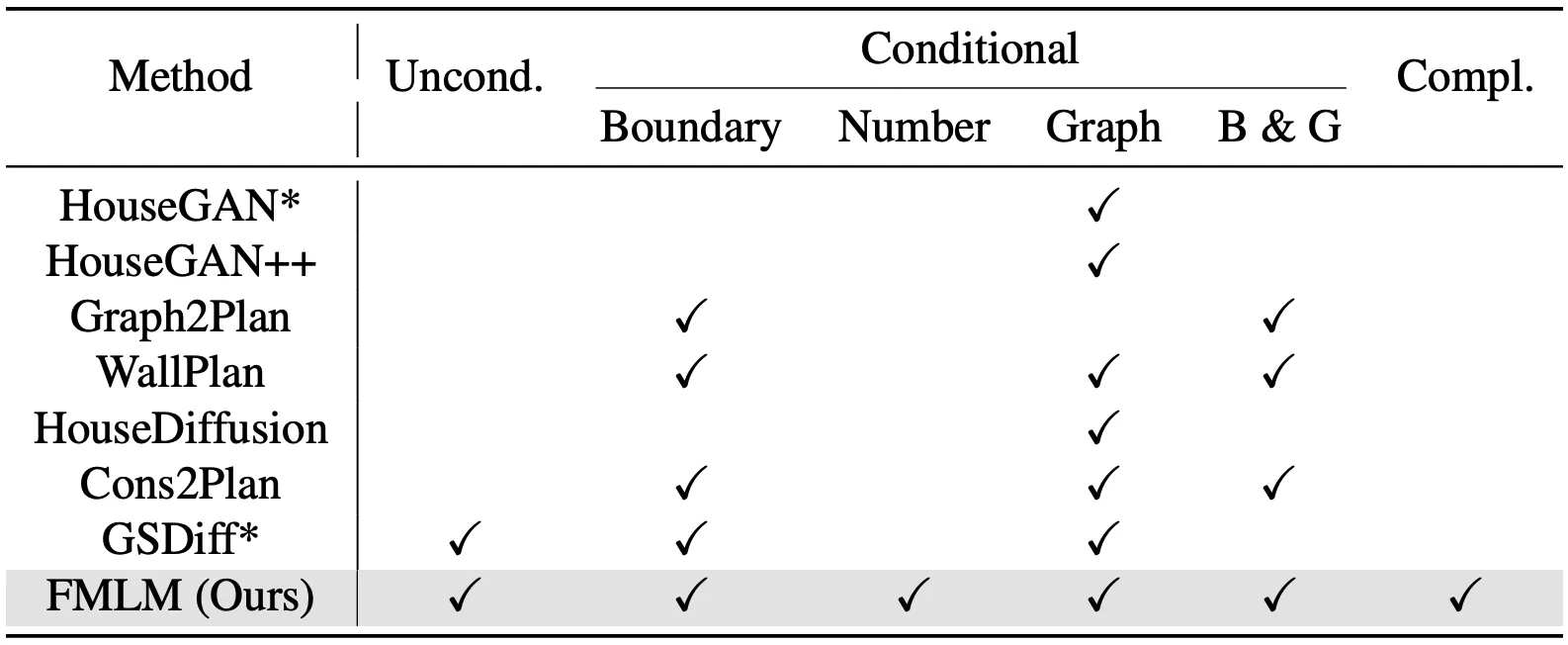
With FML, a single method can support different goals, like drawing from a building boundary, from a room graph, or from both at once. The key idea is to speak about rooms, walls, and doors using a shared markup, then let a model complete the sequence.
FML: Unified Vector Floorplan Generation via Markup Representation Overview
Project Type | Research project on vector floorplan generation Purpose | Create clean vector floorplans from flexible inputs using a shared markup Core Idea | Turn floorplan drawing into next token prediction over a markup language Main Features | One model for many tasks, variable length plans, flexible conditions Typical Inputs | Boundary lines, room graphs, or both together Typical Outputs | Vector floorplans with rooms, doors, walls Demo | Short video shows the unified method in action Project Page | FML: Unified Vector Floorplan Generation via Markup Representation
If you want a quick refresher on how code projects are shared online, check our short note on using Github.
FML: Unified Vector Floorplan Generation via Markup Representation Key Features
- One markup for everything. The same language describes rooms, doors, and walls across tasks.
- Works with any plan length. It does not need a fixed number of rooms or doors.
- Adapts to many inputs. It can draw from a boundary, a graph of rooms, or both.
- Simple next step logic. The model just picks the next token each time.
- Fewer add on parts. No extra networks needed for edge or room split rules.
- Built for general use. It supports many floorplan goals under one roof.
How FML Works
FML converts a vector floorplan into a short text like script. Each token tells the model what to draw next.
Then the model does next token prediction. It adds one token at a time until the plan is complete.
This setup makes room counts free. There is no need to set the number of rooms or doors early on.
Read More: Bytedance
FML: Unified Vector Floorplan Generation via Markup Representation Use Cases
Home design teams can sketch a boundary and get a full room layout that fits that shape. This cuts trial and error for early studies.
Real estate apps can turn simple inputs into clean floorplans for listings. This helps buyers see space and flow.
Teaching and research groups can study plan data in a shared format. The markup gives a clear way to compare many tasks.
Why this work is important
Past work often used diffusion on vertices for vector floorplans. But diffusion models did not fit well when the output length can change.
So past methods needed predefined counts of rooms and doors, or extra networks for edge finding and room split steps. In contrast, FML uses a shared markup and next token prediction so it can generalize to many input types.
Performance and Showcases
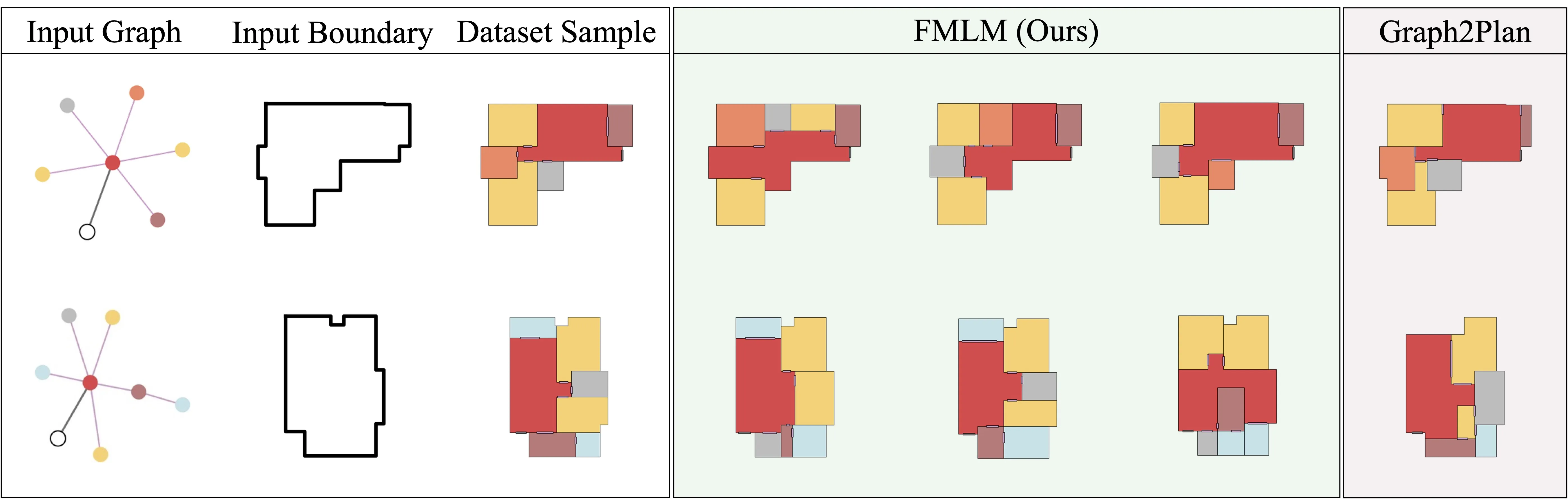
Showcase 1 — See FML turn any vector floorplan task into next token prediction Our "Floorplan Markup Language" (FML) formulates any vector floorplan generation tasks as next-token prediction. This video shows how one model handles different inputs while following the same token by token plan. You can watch how a single method grows a full layout with clear steps.
If video creation topics interest you too, have a look at our note on Goku video generation.
The Technology Behind It
Everything is driven by a Floorplan Markup Language. This turns drawing into text actions that a model can understand.
The model then does next token prediction. It adds one item at a time like a story that writes itself.
Because the plan is a token stream, it can grow or stop at any length. This makes it fit real needs with many rooms or just a few.
Installation and Setup
Below is a step by step guide to run related research code shared by the authors. Follow each step in order. Use the commands and code blocks as shown.
Recommended development environment
- GPU: NVIDIA A100
- CUDA: 11.1
- Docker: 20.10.8
1. Dataset
Download datasets and place them in ./data/ folder. For example, download Celeb DF v2 and place it:
.
└── data
└── Celeb-DF-v2
├── Celeb-real
│ └── videos
│ └── *.mp4
├── Celeb-synthesis
│ └── videos
│ └── *.mp4
├── Youtube-real
│ └── videos
│ └── *.mp4
└── List_of_testing_videos.txt
For other datasets, please refer to ./data/datasets.md .
2. Pretrained model
We provide weights of EfficientNet B4 trained on SBIs from FF raw and FF c23. Download [raw][c23] and place it in ./weights/ folder.
3. Docker
- Replace the absolute path to this repository in ./exec.sh .
- Run the scripts:
bash build.sh
bash exec.sh
Test
For example, run the inference on Celeb DF v2:
CUDA_VISIBLE_DEVICES=* python3 src/inference/inference_dataset.py \
-w weights/FFraw.tar \
-d CDF
The result will be displayed.
Using the provided pretrained model, our cross dataset results are reproduced as follows:
We also provide an inference code for video:
CUDA_VISIBLE_DEVICES=* python3 src/inference/inference_video.py \
-w weights/FFraw.tar \
-i /path/to/video.mp4
and for image:
CUDA_VISIBLE_DEVICES=* python3 src/inference/inference_image.py \
-w weights/FFraw.tar \
-i /path/to/image.png
Training
- Download FF++ real videos and place them in ./data/ folder:
.
└── data
└── FaceForensics++
├── original_sequences
│ └── youtube
│ └── raw
│ └── videos
│ └── *.mp4
├── train.json
├── val.json
└── test.json
- Download landmark detector (shape_predictor_81_face_landmarks.dat) from here and place it in ./src/preprocess/ folder.
Download landmark detector (shape_predictor_81_face_landmarks.dat) from here and place it in ./src/preprocess/ folder.
- Run the two codes to extractvideo frames, landmarks, and bounding boxes:
Run the two codes to extractvideo frames, landmarks, and bounding boxes:
python3 src/preprocess/crop_dlib_ff.py -d Original
CUDA_VISIBLE_DEVICES=* python3 src/preprocess/crop_retina_ff.py -d Original
- (Option) You can download code for landmark augmentation:
mkdir src/utils/library
git clone https://github.com/AlgoHunt/Face-Xray.git src/utils/library
Even if you do not download it, our training code works without any error. (The performance of trained model is expected to be lower than with it.)
- Run the training:
CUDA_VISIBLE_DEVICES=* python3 src/train_sbi.py \
src/configs/sbi/base.json \
-n sbi
Top five checkpoints will be saved in ./output/ folder. As described in our paper, we use the latest one for evaluations.
If you are new to repos and pulls, here is a short refresher on working with Github.
Tips for Better Results
Start with a clear boundary or a clean room graph. The markup works best when the inputs are neat.
Check outputs step by step. If a token looks off, rethink the last inputs and try again.
Save your sequences. The markup is easy to store, compare, and reuse later.
FAQ
What makes FML different from past floorplan methods?
Past methods often needed a fixed count of rooms and doors. FML does not need that and can grow plans of any length. It uses a shared markup so one model can serve many tasks.
Can FML work with only a building outline?
Yes. You can give a boundary and get a room layout that fits that shape. The same model can also take a room graph or both at the same time.
Do I need extra steps to find edges or split rooms?
No extra networks are needed. The next token process covers those steps inside the markup flow. This keeps the setup simple.
Is there a demo I can watch?
Yes. The showcase video in this page shows the idea in action. It shows how the model builds a plan token by token.
Image source: FML: Unified Vector Floorplan Generation via Markup Representation