Navigating the Future: How VLingNav Combines Adaptive Reasoning and Visual Memory
What is Navigating the Future: How VLingNav Combines Adaptive Reasoning and Memory
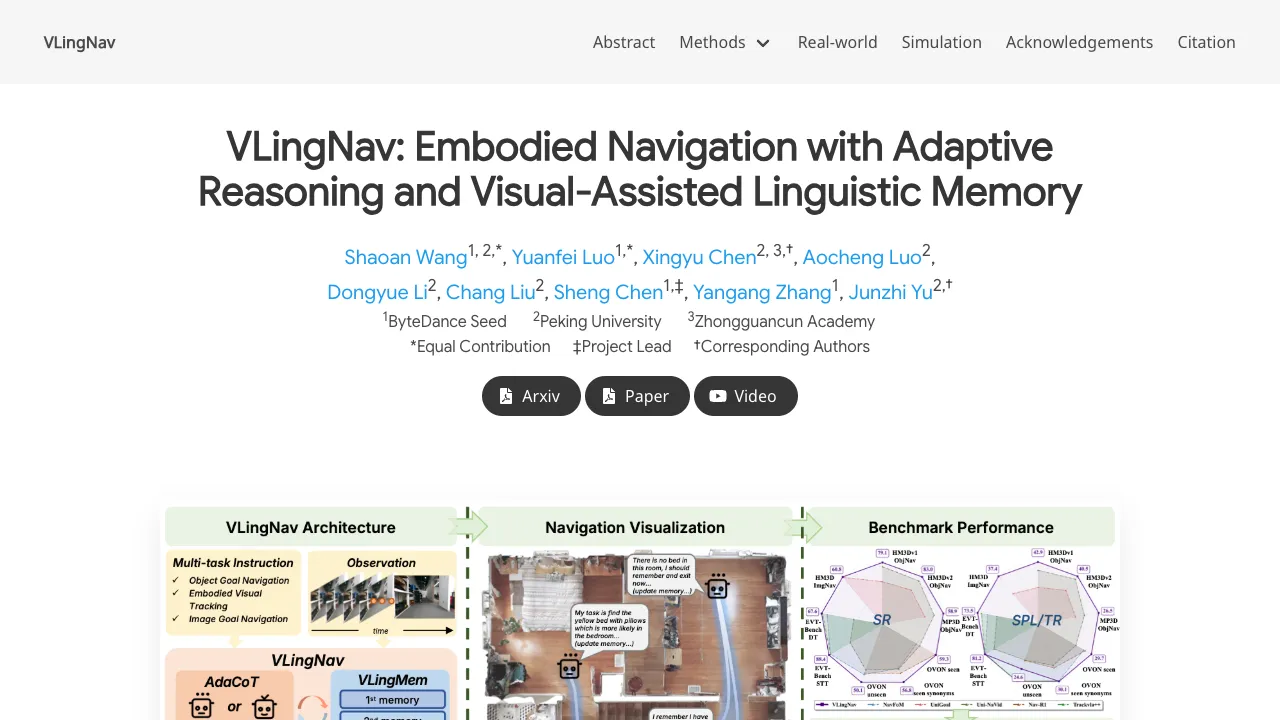
VLingNav is a research project that helps robots move through real spaces using a camera feed and a short text instruction, like “ the kitchen and look for the red cup.” It mixes fast reactions with careful step-by-step thinking, and it keeps a long-term memory to avoid walking in circles.
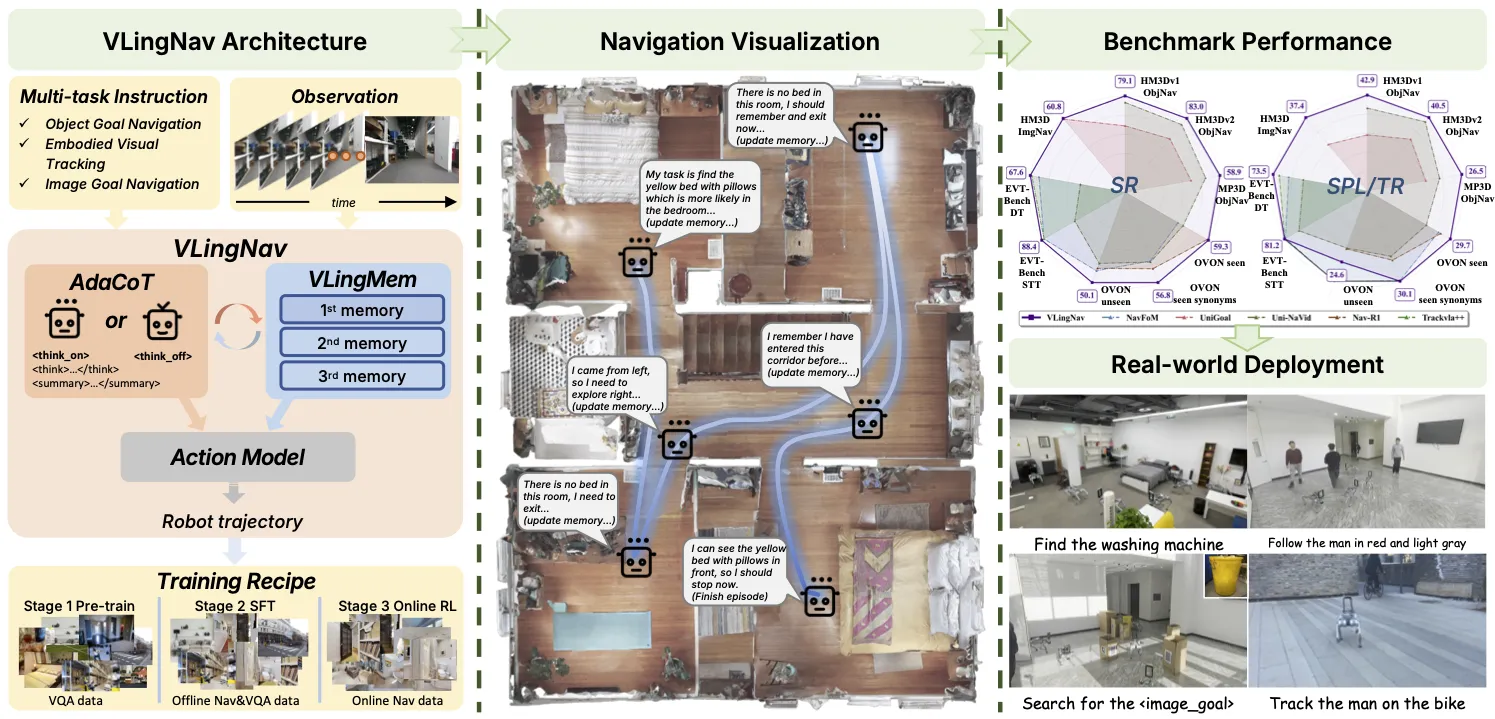
The team calls this mix “adaptive chain-of-thought” for planning and a language-based memory that is aided by what the camera sees. Together, they help the robot act quickly when the path is easy and slow down to plan when the task is tricky. You can explore the project page here: VLingNav website.
Read More: Omnihuman 1.Com
Navigating the Future: How VLingNav Combines Adaptive Reasoning and Memory Overview
Here is a quick summary of the project at a glance.
| Item | Details |
|---|---|
| Project Name | VLingNav |
| Type | Vision-Language-Action (VLA) navigation research and demos |
| Purpose | Help robots follow natural language directions and move in real spaces |
| Inputs | Live video stream + text instruction |
| Outputs | Action commands for a robot to move and turn |
| Key Ideas | Adaptive chain-of-thought (AdaCoT), language memory tied to camera input (VLingMem), online expert-guided training |
| Dataset | Nav-AdaCoT-2.9M with 2.9 million step-by-step reasoning paths |
| Training | Imitation learning plus an online stage guided by an expert |
| Transfer | Works on real robots without extra training on those robots (zero-shot) |
| Website | Project page |
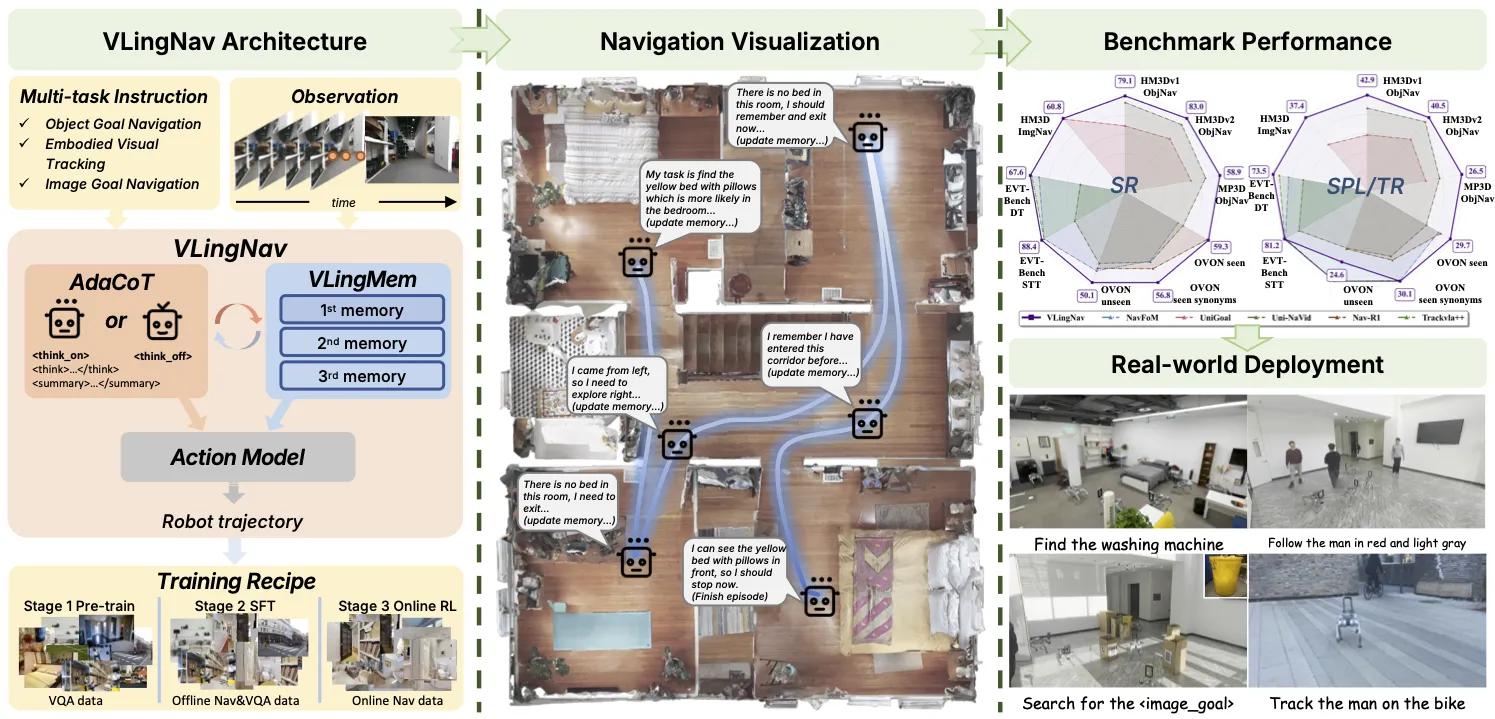
Navigating the Future: How VLingNav Combines Adaptive Reasoning and Memory Key Features
-
Adaptive chain-of-thought (AdaCoT). The robot acts fast when the way is clear and thinks step by step only when needed. This saves time and still keeps plans smart.
-
Language memory with camera help (VLingMem). The robot builds a long-term memory using words that describe what the camera saw earlier. This helps it avoid repeat paths and keep track of moving things.
-
Nav-AdaCoT-2.9M dataset. The team made a very large dataset with 2.9 million steps that include reasoning notes. These notes teach the model not just what to do, but also when to think and what to think about.
-
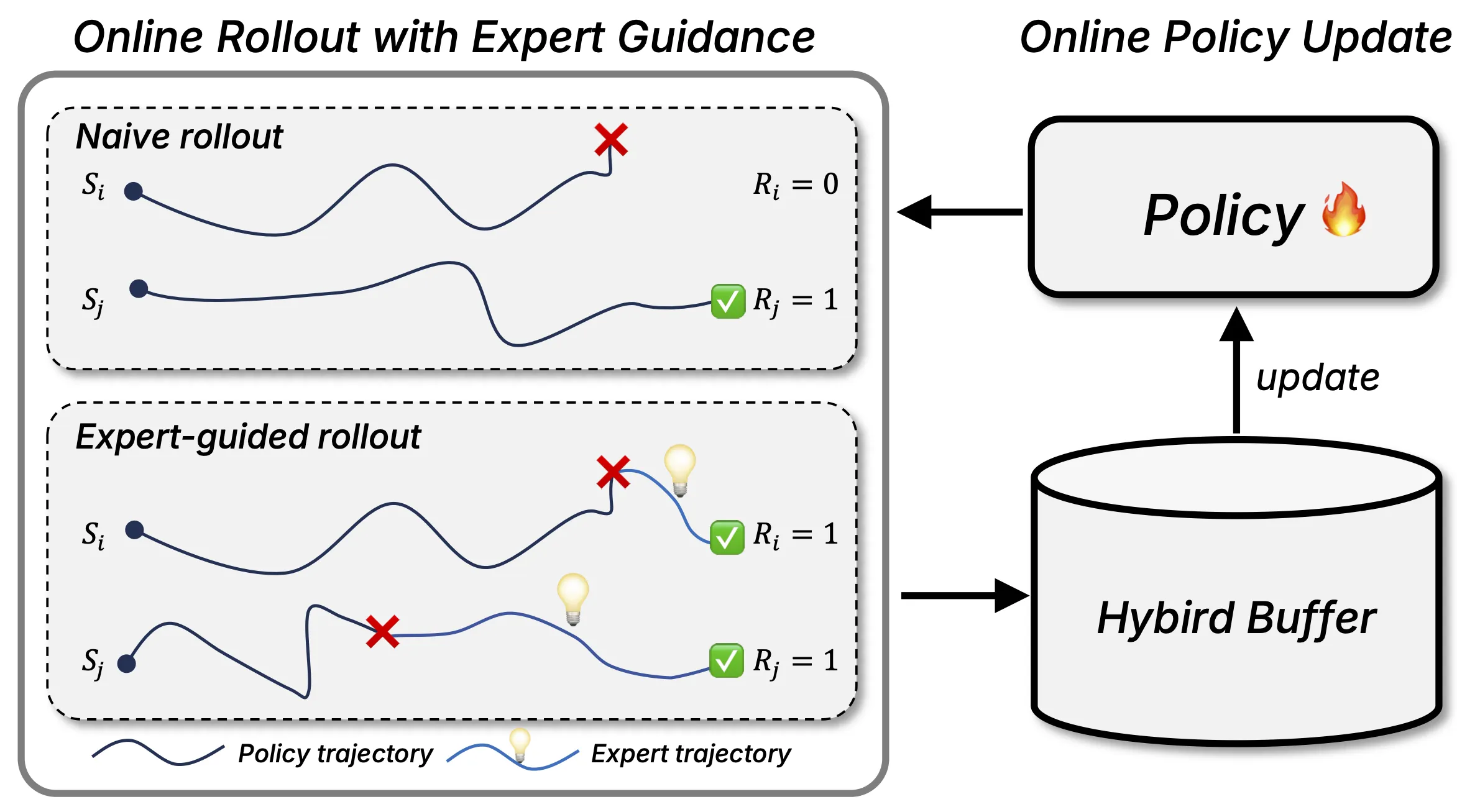
Online expert-guided training. After learning from recorded data, the model also trains in a live loop with guidance from a teacher signal. This helps it act better in the real world.
-
Strong transfer to real robots. The model can run on real robot platforms without extra fine-tuning for each robot. It handles new rooms and new tasks that it did not see before.
Read More: About
Navigating the Future: How VLingNav Combines Adaptive Reasoning and Memory Use Cases
-
Home help. A home robot can follow short voice or text commands to reach a room or find an item.
-
Office and campus. A robot guide can move between rooms and deliver small items while avoiding repeat loops.
-
Warehousing. A mobile unit can a shelf row, scan for a color or label, and return by the shortest route it learned.
-
Safety patrol. A robot can follow a path, track changes, and remember what it saw on past loops.
Performance & Showcases
Showcase 1 — Summary Video (Label: 1). This summary clip shows the system acting on a short instruction and reacting to what the camera sees. It is tagged as Label: 1.
Showcase 2 — Summary Video (Label: 1). You see how planning and quick actions work together in one pass. This clip is also marked Label: 1.
Showcase 3 — Summary Video (Label: 1). The video highlights how memory prevents repeat paths in longer tasks. It carries the tag Label: 1.
Showcase 4 — Summary Video (Label: 1). Watch how the agent follows a request and adjusts when the scene changes. The label shown is Label: 1.
Showcase 5 — Summary Video (Label: 1). This demo points out step-by-step thinking kicking in only when needed. It is listed under Label: 1.
Showcase 6 — Summary Video (Label: 1). The clip shows steady moves, planning, and memory in one run. It appears with Label: 1.
How VLingNav Works
VLingNav takes in a video stream plus a text instruction. From this, it picks an action like “move forward,” “turn left,” or “turn right.”
When the path is simple, it acts fast. When the path gets tricky, it starts a chain-of-thought plan that explains each step in plain words inside the model. As it moves, it keeps a language memory tied to what the camera saw, so it can recall rooms, objects, and past steps.
The Technology Behind It (In Simple Words)
-
Two modes of thinking. One is fast and instinctive for clear paths. The other is slow and careful for hard spots.
-
Memory that lasts. The system builds a long-term memory using short word notes linked to earlier views. This prevents loops and helps in changing rooms.
-
Learn by watching, then by doing. First, it learns from recorded data with step notes. Then it trains live with an expert signal that helps it fix weak spots.
For a short note on industry trends, see this brief page: Bytedance.
Getting Started (Installation & Setup)
This project page is a public website for research news, a method overview, and demos. There are no install commands in the site repo.
- Visit the main page here: VLingNav website.
- Watch the summary videos and read the method notes on the page.
- Check the dataset and method figures to learn how the model thinks and remembers.
FAQ
What problems does VLingNav try to solve?
Most robot navigation models act only on the latest camera frame. VLingNav adds smart planning only when needed and keeps a long-term memory, so it can handle long trips and not get stuck repeating steps.
How does the memory help in plain words?
It writes short word notes about what the camera saw in past steps and keeps those notes. Later, it reads those notes to avoid going back to the same spots and to track moving things.
Can this work on real robots?
Yes, the team shows runs on real robots without extra fine-tuning for each robot. The same model can handle new places and new tasks it did not see in training.
What is special about the training data?
The dataset, called Nav-AdaCoT-2.9M, has 2.9 million step notes with when-to-think and what-to-think hints. This helps the model learn both quick actions and thoughtful plans.
Does it only follow one type of instruction?
It reads short text prompts that describe the goal, like room names or objects. Then it turns those into a plan and a set of moves.
Image source: Navigating the Future: How VLingNav Combines Adaptive Reasoning and Memory