Vidi 2.5: The Next Frontier in High-Fidelity Video Generation
What is Vidi 2.5: The Next Frontier in High-Fidelity Video Generation
Vidi 2.5 is a family of AI models that can understand videos and help create them. It can find the exact moment a thing happens, draw boxes around objects, answer questions about a video, and even plan edits for an end-to-end cut.
It builds on earlier Vidi releases and adds stronger spatio-temporal grounding, better temporal retrieval, and a new “Think” mode for plot understanding. There is also Vidi-Edit, which can turn raw clips into a structured editing plan with music, scene order, and effects.
Vidi 2.5: The Next Frontier in High-Fidelity Video Generation Overview
Here is a simple snapshot of the project.
| Field | Details |
|---|---|
| Project | Vidi 2.5: Large Multimodal Models for Video Understanding and Creation |
| Type | Large multimodal video model family |
| Purpose | Video understanding, search, grounding, Q&A, and editing planning |
| Maintainer | ByteDance Vidi Team |
| Latest Release | 01/20/2026 (Vidi2.5) |
| Website | https://bytedance.github.io/vidi-website/ |
| Live Demo | https://vidi.byteintl.com/ |
| Main Modes | “Grounding”, “Retrieval”, “Chapter”, “Highlight”, “VQA”, “Thinking” |
| Key Features | Spatio-temporal grounding (boxes + time), temporal retrieval, video Q&A, plot reasoning (Vidi2.5-Think), auto chapters, auto highlights, edit planning (Vidi-Edit) |
| Benchmarks | VUE-STG (grounding), VUE-TR-V2 (retrieval), VUE-PLOT (plot understanding) |
| Notable Models | Vidi2.5-Think, Vidi1.5-9B, Vidi-7B |
| Inputs | MP4 video, English text query or question |
| Outputs | Timestamps, bounding boxes, answers, chapters, highlight clips, editing plan |
| Reported Results | Stronger STG; slightly better TR and Video QA than Vidi2; strong plot understanding in Vidi2.5-Think |
If you are new to this topic, see our short primer on text-to-video tools: text-to-video guide.
Vidi 2.5: The Next Frontier in High-Fidelity Video Generation Key Features
-
Spatio-temporal grounding (STG): Given a text query, the model finds the right time and draws bounding boxes on the target object. This is great for edits that need precise object tracking and timing.
-
Temporal retrieval (TR): Search a long video with a sentence and get back the exact parts that match. This saves hours of scrubbing.
-
Video Q&A and Thinking: Ask questions and get answers. Use “Thinking” for plot-heavy clips that need step-by-step reasoning.
-
Auto “Chapter” and “Highlight”: Get clean chapters or highlight clips without writing prompts. This is handy for long videos.
-
Vidi2.5-Think and VUE-PLOT: Strong character tracking and plot reasoning on the new VUE-PLOT benchmark.
-
Vidi-Edit: Produces a structured editing plan, including story order, audio notes, and edit intent.
Looking for a related system that focuses on generation? Here is a quick look at another project: Goku video model.
How Vidi 2.5 Works
- You give the model a video and a short text query or question. The system breaks the video into chunks, checks both space (what is in the frame) and time (when it happens), and then returns results.
- For grounding, it gives you timestamps and bounding boxes. For retrieval, it gives you the right time ranges. For Q&A, it gives clear answers.
- Vidi2.5 is trained with extra feedback to improve results. The “Think” mode adds step-by-step reasoning for story-heavy videos.
Getting Started: Installation & Setup
You can test the official benchmarks locally. Follow the commands below exactly.
Evaluate VUE-STG (Spatio-Temporal Grounding)
These files include video IDs, ground-truth labels, and sample results.
cd VUE_STG
python3 evaluate.py
To evaluate your own model:
- First download the videos based on the ids in "VUE_STG/vue-stg-benchmark/video.csv" from Youtube (e.g., yt-dlp ).
- Generate the result following the format in VUE_STG/results/vidi2/tubes.csv. Run evaluation script.
Evaluate VUE-TR-V2 (Temporal Retrieval)
Ground-truth labels and results come in 5 JSON files. Run:
cd VUE_TR_V2
bash install.sh
python3 -u qa_eval.py --pred_path results_Vidi.json
The result figures will be saved in the output folder ('./results' by default) .
For new models, download videos listed in VUE_TR_V2/video_id.txt (e.g., with yt-dlp), run inference, and save results like this:
[
{
"query_id": 0,
"video_id": "6Qv-LrXJjSM",
"duration": 3884.049,
"query": "The slide showcases Taco Bell's purple ang pow for Chinese New Year, while a woman explains that purple symbolizes royalty in the Chinese tradition.",
"answer": [
[
913.1399199,
953.5340295
]
],
"task": "temporal_retrieval"
},
...
]
Model Inference and Finetune
- To conduct inference and finetuning for Vidi1.5-9B, follow the instructions in Vidi1.5_9B/README.md.
- To conduct inference for Vidi-7B, follow the instructions in Vidi_7B/README.md.
Try the Online Demo (Vidi and Vidi-Edit)
- Visit https://vidi.byteintl.com/.
- Pick a mode: “Grounding”, “Retrieval”, “Chapter”, “Highlight”, “VQA”, or “Thinking”.
- Click Upload and choose an MP4 file. 480p is recommended for speed.
- Enter a text query if the mode needs it, then click Send.
- Wait for the result clips in the chat box. Longer videos take more time.
For multi-clip auto editing, select the “Edit” page, upload several videos, and click Generate to get a full edited output with storyline, music, and effects.
Vidi 2.5: The Next Frontier in High-Fidelity Video Generation Use Cases
-
Fast editing: Find every moment of “the red car turns left,” with boxes and time ranges you can cut to right away.
-
Sports and events: Pull highlight reels and chapters without manual clipping.
-
Plot-heavy videos: Track characters, follow story lines, and answer tough questions with “Thinking.”
-
Education and search: Jump to the right explanation part in a long lecture. Use Q&A for quick checks.
-
Safety/compliance: Locate when a certain object appears and confirm it with bounding boxes.
-
Auto post-production: Use Vidi-Edit to draft a ready-to-review edit plan with beats, effects, and structure.
If you are exploring broader human-video model families, our quick explainer on Omnihuman 1.5 model can help you compare approaches.
Performance & Showcases
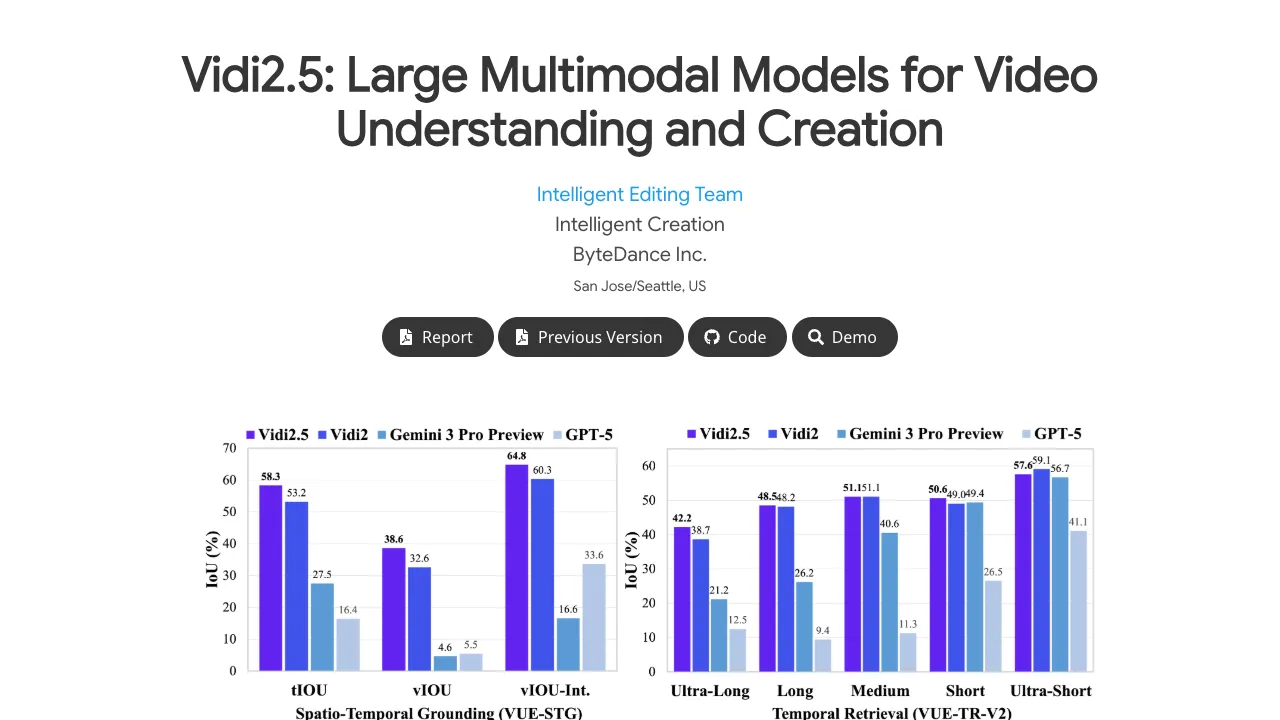
Vidi2.5 improves spatio-temporal grounding and keeps strong retrieval and Q&A ability. It reports strong results on VUE-STG, VUE-TR-V2, and VUE-PLOT, and shows real-world value in editing planning.
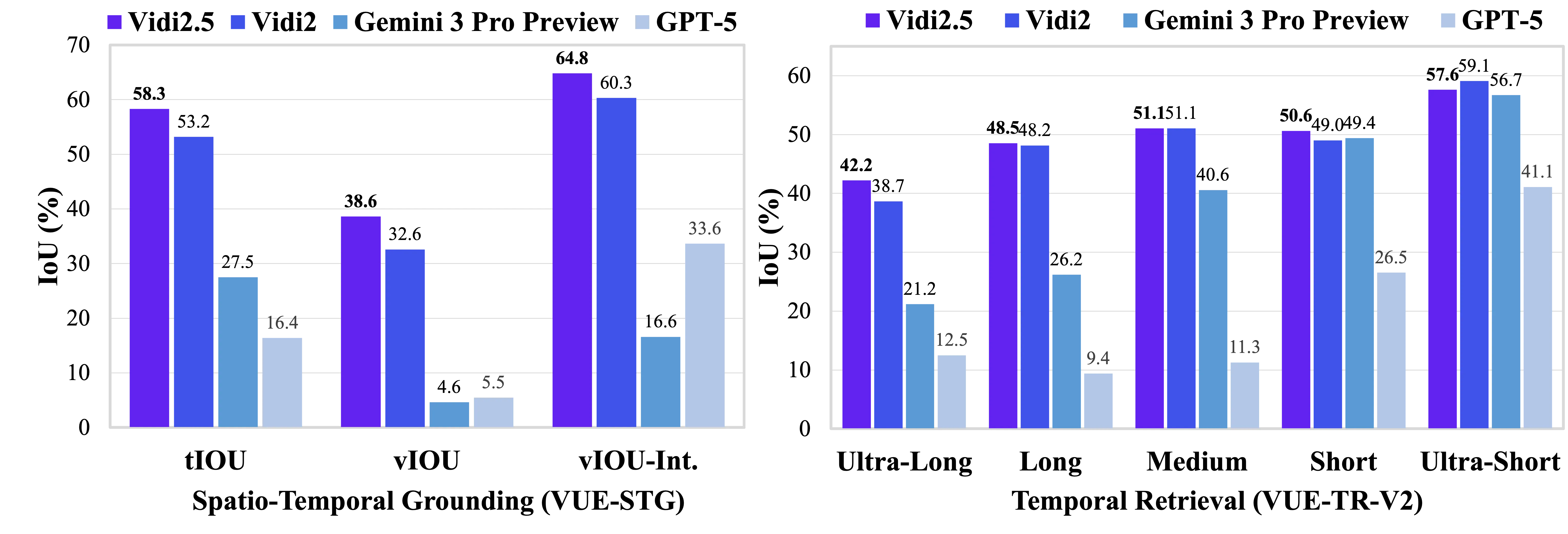
Showcase 1 — Spatio-Temporal Grounding This demo highlights how the model pinpoints the right time and adds boxes on target objects. You will see the phrase Spatio-Temporal Grounding in action across different scenes. It shows how queries map to exact shots and areas.
Showcase 2 — Spatio-Temporal Grounding Here, the system responds to a text query by finding the clip and drawing the box on the object. The aim is clear timing and location, summed up by Spatio-Temporal Grounding. It helps editors jump straight to the right cut.
Showcase 3 — Spatio-Temporal Grounding This video shows consistent Spatio-Temporal Grounding under varied motion and backgrounds. The output makes it easy to confirm both where and when things happen. It reduces guesswork in long footage.
Showcase 4 — Spatio-Temporal Grounding Watch Spatio-Temporal Grounding across multiple moments in one video. The model keeps track of the target object over time and returns clean timestamps. Each result is ready for edit or review.
Showcase 5 — Spatio-Temporal Grounding In this sample, Spatio-Temporal Grounding handles clutter and quick changes. Timestamps and boxes match the text instruction closely. This gives a strong base for fast trimming.
Showcase 6 — YouTube video player This example is provided through a YouTube video player for easy viewing. The same interface and flow apply to longer clips as well. Use the YouTube video player to compare outputs across tasks.
The Technology Behind It
Vidi is a large multimodal model family made for video understanding and creation tasks. It works across time and space, and is trained with extra feedback to get better results on grounding, search, and Q&A. The Vidi2.5-Think variant adds stronger plot reasoning.
VUE-STG checks fine-grained grounding, VUE-TR-V2 checks retrieval balance, and VUE-PLOT checks character tracking and story logic. Reports show Vidi2.5-Think doing well for character-level understanding and competitive plot reasoning. Vidi-Edit shows that the model can move beyond lab tests into editing workflows.
Step-by-Step: Try the Online Demo
- Pick a mode:
- “Grounding” finds clips and draws boxes on the object in your query.
- “Retrieval” returns the time ranges that match your text.
- “Chapter” outputs chapters with titles.
- “Highlight” outputs highlight clips with titles.
- “VQA” answers a question about the video.
- “Thinking” reasons step by step before answering.
- Upload MP4, wait for the player to show it is ready, then click Send.
- Results appear in the chat area. For long videos, give it a little time.
FAQ
What is spatio-temporal grounding?
It means the model finds when something happens and where it is in the frame. You get timestamps and bounding boxes for the object you ask about. This is useful for edits that need exact cuts.
How long can my video be?
There is no fixed public limit, but longer videos need more time to process. For quick tests, 480p is suggested for upload and decode speed. The web demo works best with clean MP4 files.
Is the project open to try?
Yes, there is a public demo you can use in your browser. There are also evaluation scripts and data you can run locally to test your own model. Check the links above for details.
Image source: Vidi 2.5: The Next Frontier in High-Fidelity Video Generation