Beyond the Sandbox: Mastering Real-World Computer Tasks with OSWorld

What is Beyond the Sandbox: ing Real-World Computer Tasks with OSWorld
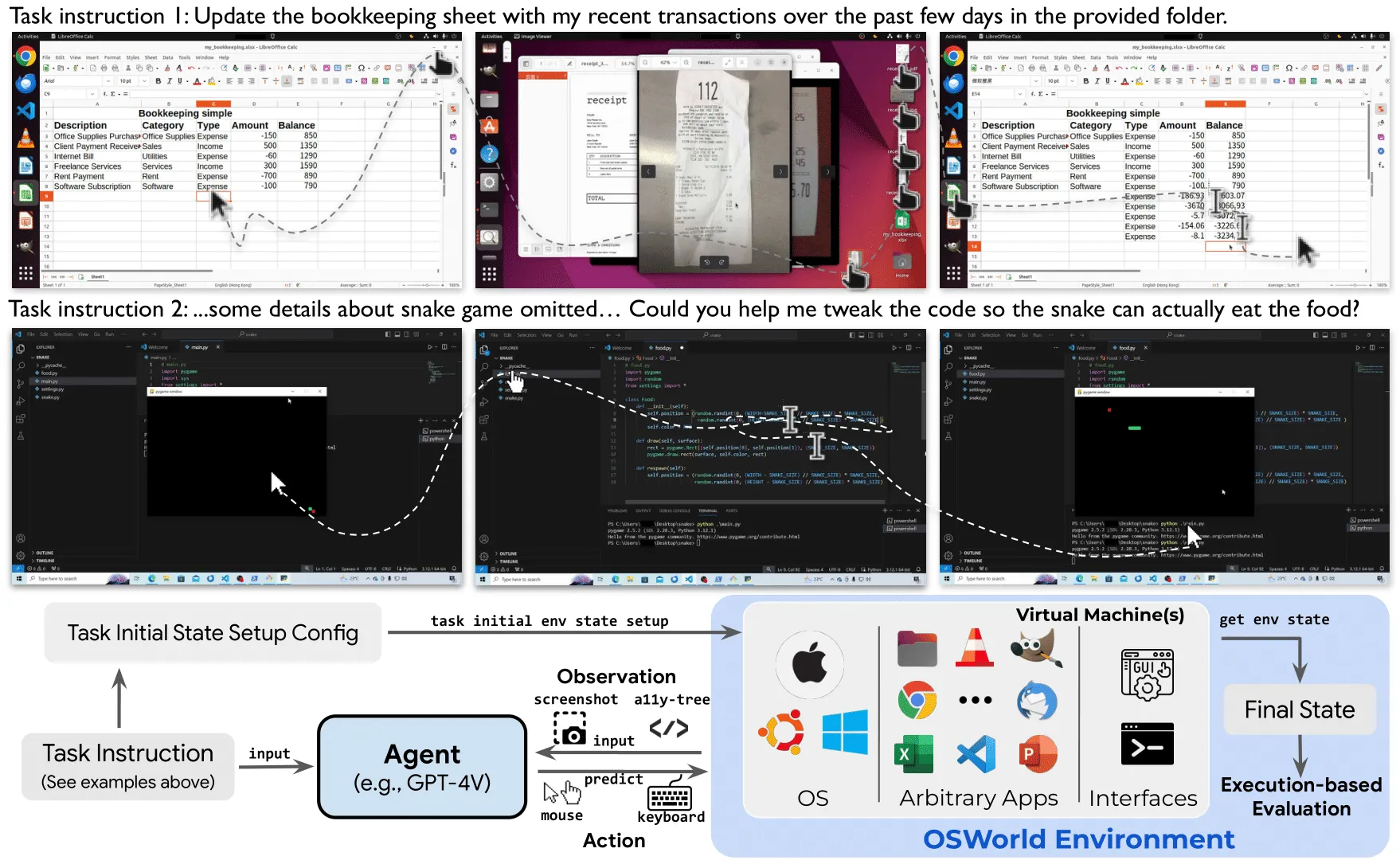
OSWorld is a test world for computer agents. It checks if an AI can really use a computer to finish real tasks in apps like Chrome, GIMP, LibreOffice, Thunderbird, VLC, and VS Code. It focuses on full, real steps on a desktop, not just small toy clicks.
It gives a clean way to compare different AI systems. You can see clear scores, watch full step-by-step runs, and match your numbers to official results.
Beyond the Sandbox: ing Real-World Computer Tasks with OSWorld Overview
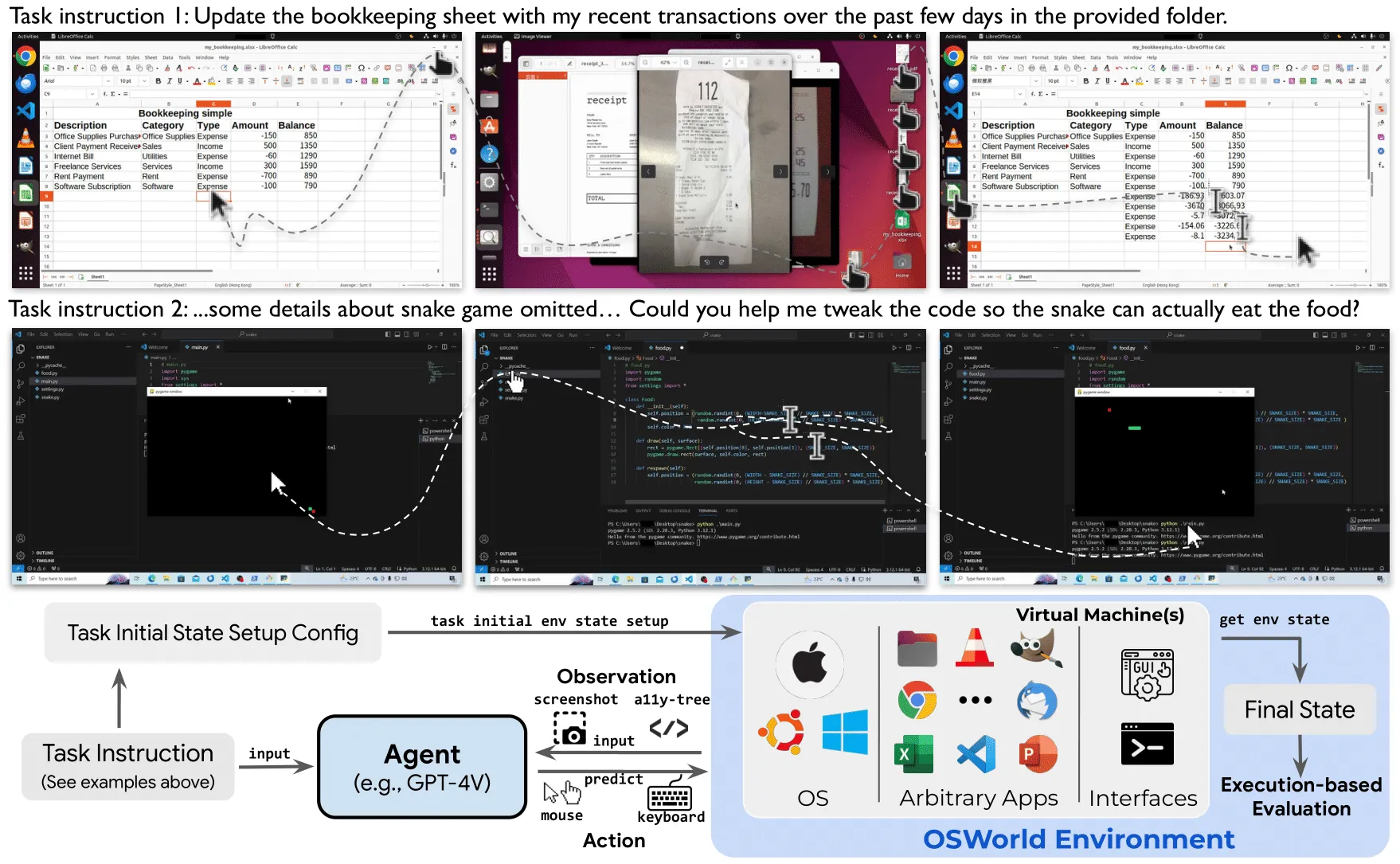
OSWorld tracks how well agents handle 369 real tasks across many desktop apps. It offers an “OSWorld-Verified” mode, so results match the official rules and setup.
- Read more AI stories on our site.
Project Overview
| Item | Details |
|---|---|
| Type | Desktop task suite, benchmark, and evaluation platform |
| Purpose | Test how well AI agents can complete full computer tasks end to end |
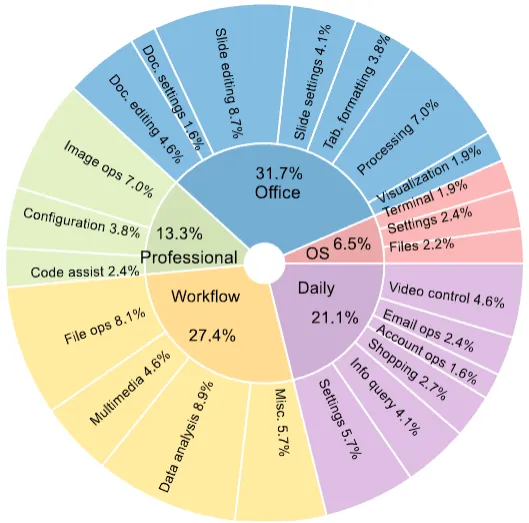
| Task Count | 369 tasks across Chrome, GIMP, LibreOffice Calc/Impress/Writer, Thunderbird, VLC, VS Code, and multi-app workflows |
| OSWorld-Verified | Yes. Updated benchmark, fixed community-reported examples, AWS support to finish runs in about 1 hour |
| Models Covered | General models and specialized models, plus agentic frameworks |
| Key Metrics | Success rate by app and overall, under fixed max steps (15/30/50/100) |
| Data Access | Verified trajectories are hosted on Hugging Face for study |
| Network Notes | Proxy setup guidance provided; pre-configured option via DataImpulse |
| Google Drive Notice | 8 tasks may need manual setup; it is fine to exclude them for fair comparison |
| Official Site | https://os-world.github.io/ |
Beyond the Sandbox: ing Real-World Computer Tasks with OSWorld Key Features
- Real computer use. Agents move the mouse, type, open apps, and finish full jobs, not just single clicks.
- Broad app coverage. Tasks span Chrome, GIMP, LibreOffice (Calc, Impress, Writer), Thunderbird, VLC, VS Code, plus multi-app tasks.
- OSWorld-Verified mode. The team fixed known examples, added AWS support to cut run time to within 1 hour, and refreshed benchmark scores.
- Clear scoring. Results show success rates by app and overall, under the same step limits and rules.
- Open progress. Verified runs live on Hugging Face so people can inspect every step.
- Ongoing updates. The benchmark adds new LLMs, VLMs, and methods over time, with pull requests welcome.
- Network help. There is a proxy setup guide and a pre-configured option via DataImpulse to make setup easier.
- Fair choices for Google Drive tasks. You can either adjust 8 tasks by hand or skip them (361 tasks total). Both are valid for the leaderboard.
How OSWorld Works
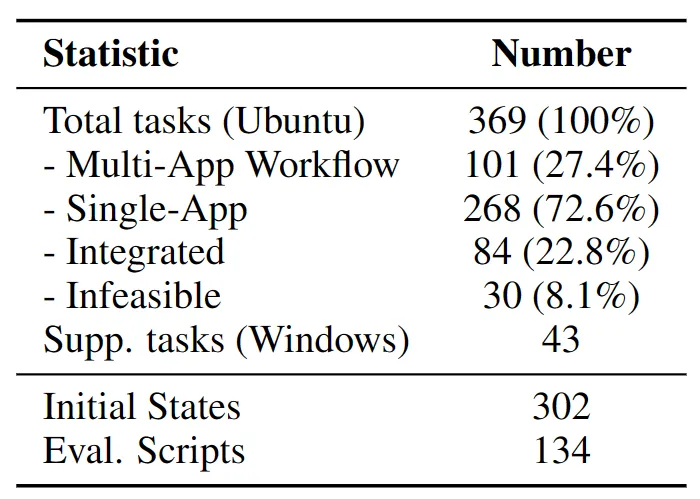
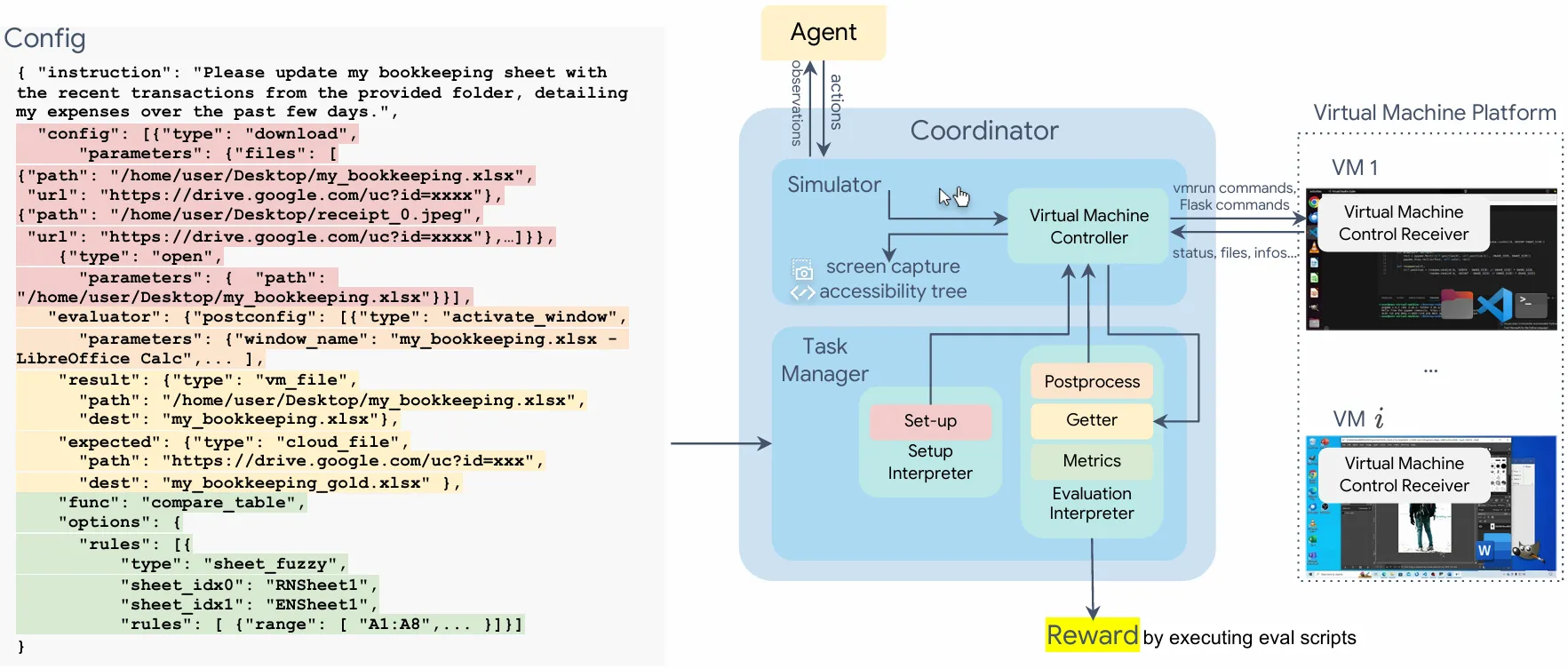
An agent gets the task goal. Then it “sees” the screen, clicks, types, and moves through apps. The system records each step, checks if the goal is reached, and scores the run.
You can choose a max number of steps (for example, 50 or 100). The same rules apply to all models to keep things fair.
OSWorld also offers a verified mode with set configs and AWS help. This keeps results aligned with the official benchmark and cuts run time to within 1 hour.
- Want context on one of the teams in the results? See our short profile on ByteDance.
The Technology Behind It
OSWorld compares three broad ideas:
- General model: a broad model that can chat, code, and also use a computer when asked.
- Specialized model: trained mainly for computer-use tasks.
- Agentic framework: a setup that links models in roles, like a planner plus a tool-focused helper.
These styles face the same tests. Scores show who finishes more tasks under the same limits.
Beyond the Sandbox: ing Real-World Computer Tasks with OSWorld Use Cases
- Research: Check if a new model truly completes desktop work. Compare to official runs.
- Product teams: Test agent features across common apps before shipping.
- Education: Teach how real computer agents reason through tasks, step by step.
- Content makers: Show full runs with clear outcomes for your audience.
- Cloud and ops: Use the verified mode and AWS support to finish evals fast.
If you want to know who we are and what we cover, visit our about page.
Installation & Setup (Getting Started)
- Check the Setup Guideline on proxy configuration. A pre-configured option based on DataImpulse is available.
- Be aware of 8 Google Drive tasks that can have setup issues due to IP or network factors. You have two valid choices: adjust these 8 tasks by hand to run all 369, or exclude them and run 361. Both are allowed for fair comparison and leaderboard.
- Use OSWorld-Verified mode to match official settings. With AWS support, evaluation can finish within about 1 hour.
- Compare your results with the latest “OSWorld-Verified” benchmark. The team fixed community-reported examples and refreshed the scores.
- For deep study, review the verified run histories on Hugging Face.
Tips for Better Scores
- Higher screen-shot resolution often helps. Clearer screens can make agents less likely to miss on-screen details.
- Longer text history of past steps can help more than screen-only history, but it can slow things down.
- Current agents can be sensitive to layout changes and noise on the screen.
- Scores are strongly related across different OS types, so lessons often carry over.

Performance & Showcases
Below are official highlights from the public results and demos.
Top recent score: claude-sonnet-4-6 (General model) reached 72.1% on Mar 8, 2026 with Max Steps 100 (256.71/356). Results list per-app success across Chrome, GIMP, LibreOffice apps, Thunderbird, VLC, VS Code, multi-app, and OS tasks. Many other teams, such as ByteDance Seed, Moonshot AI, and more, also reported strong runs under shared rules.
Showcase 1 — 2025-07-28: Major Upgrade! OSWorld has been enhanced and is now OSWorld-Verified with comprehensive improvements: fixed community-reported examples, AWS support reducing evaluation time to within 1 hour, and updated benchmark results. See the verified benchmark results in the Benchmark section below. Please compare your OSWorld results with the new benchmark results when running the latest version.
Showcase 2 — @Yannic Kilcher
Showcase 3 — @Wes Roth
Showcase 4 — @hu-po
Showcase 5 — GPT-6 Leaks: Truth or Fiction?
Showcase 6 — @WorldofAI
Practical Notes for Running Benchmarks
- Use the same max-steps setting that the leaderboard uses (for example, 50 or 100). This makes your score easier to compare.
- Keep your environment stable. If network factors change (like IP), Google Drive tasks may need attention.
- When you publish your numbers, share your exact setup and link to your runs. This helps others check and learn.
FAQs
How many tasks are in OSWorld?
There are 369 tasks. If you skip the 8 Google Drive tasks due to setup issues, you will run 361 tasks. Both paths are valid for the leaderboard.
What apps are covered?
Tasks span Chrome, GIMP, LibreOffice Calc, Impress, Writer, Thunderbird, VLC, and VS Code. There are also multi-app and OS-level tasks.
What is the difference between a General model, a Specialized model, and an Agentic framework?
A General model is broad and can do many things, including computer use. A Specialized model is trained mainly for computer-use tasks. An Agentic framework links one or more models into roles, such as a planner model plus a task-focused helper.
Can I skip the Google Drive tasks and still compare my score?
Yes. You have two valid choices: adjust those 8 tasks by hand and run all 369, or exclude them and run 361. Both are accepted for benchmark comparison and leaderboard.
Where can I see detailed step-by-step runs?
All verified trajectories are hosted on Hugging Face. You can study how each agent moved through the task, step by step.
How should I report results now that OSWorld-Verified is live?
Use the latest OSWorld-Verified setup. Compare your numbers with the updated benchmark and note your max-steps setting.
Image source: Beyond the Sandbox: ing Real-World Computer Tasks with OSWorld