Supercharging GPU Performance: How CUDA Agent Automates High-Speed Kernel Generation with RL

What is Supercharging GPU Performance: How CUDA Agent Automates High-Speed Kernel Generation with RL
CUDA Agent is a research project that writes and speeds up GPU code on its own using reinforcement learning (RL). In simple words, it learns to produce faster CUDA kernels that make deep learning run quicker.

It focuses on real speed, not just passing tests. Every kernel must be correct and at least 5% faster than a strong baseline called torch.compile.
For related background on the company roots and research ties, see our short read on Bytedance.
Supercharging GPU Performance: How CUDA Agent Automates High-Speed Kernel Generation with RL Overview
Here is a quick summary of what the project is and why it matters.
| Item | Details |
|---|---|
| Type | RL-driven system that writes and tunes CUDA kernels |
| Purpose | Make PyTorch workloads faster by generating high-speed custom kernels |
| Who It’s For | AI researchers, ML engineers, CUDA learners, and performance teams |
| Main Features | Data synthesis at scale, skill-aware coding loop, strict checks, stable long-context RL training, agent workspace (agent_workdir) |
| Dataset | CUDA-Agent-Ops-6K (6,000 training tasks) |
| Agent Workspace | SKILL.md, model.py/model_new.py, kernels/, bindings, compile and verification tools |
| Speed Results (Overall) | 96.8% faster rate vs. torch.compile and 2.11x geomean speed-up |
| Speed Results (Level-3) | 90% faster rate vs. torch.compile and 1.52x geomean speed-up |
| Latest News | 2026.02.27: agent workdir added to GitHub; dataset released on Hugging Face |
| Project Site | https://cuda-agent.github.io/ |
| GitHub | https://github.com/BytedTsinghua-SIA/CUDA-Agent |
For more friendly explainers and tech highlights, visit our home base at Omnihuman 1.Com.

Supercharging GPU Performance: How CUDA Agent Automates High-Speed Kernel Generation with RL Key Features
- Agentic RL for kernel coding: The model writes CUDA, compiles it, checks it, profiles it, and improves it over many steps.
- High-quality data: A 6,000-sample training set (CUDA-Agent-Ops-6K) built from real PyTorch and Transformers ops, with strict filters.
- Skill-aware environment: Clear rules (SKILL.md), protected tools, and fair rewards that push real speed gains.
- Long-context training: Stable multi-stage RL with warm-up, smart filtering, and value pretraining for reliable learning.
- Full agent workspace: A ready folder (agent_workdir) to build, verify, profile, and iterate on CUDA extensions.
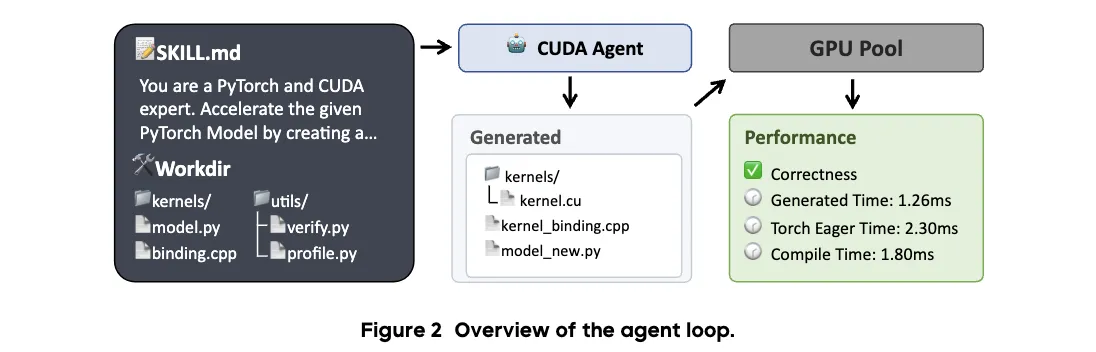
Supercharging GPU Performance: How CUDA Agent Automates High-Speed Kernel Generation with RL Use Cases
- Speed up custom model parts that torch.compile does not push far enough.
- Reduce training or inference time for heavy PyTorch workloads.
- Teach students and new engineers how real GPU optimization works in practice.
- Compare kernel quality across tasks with a strong, repeatable setup.
To learn about the people and values behind our work, visit our About page.
Performance & Showcases
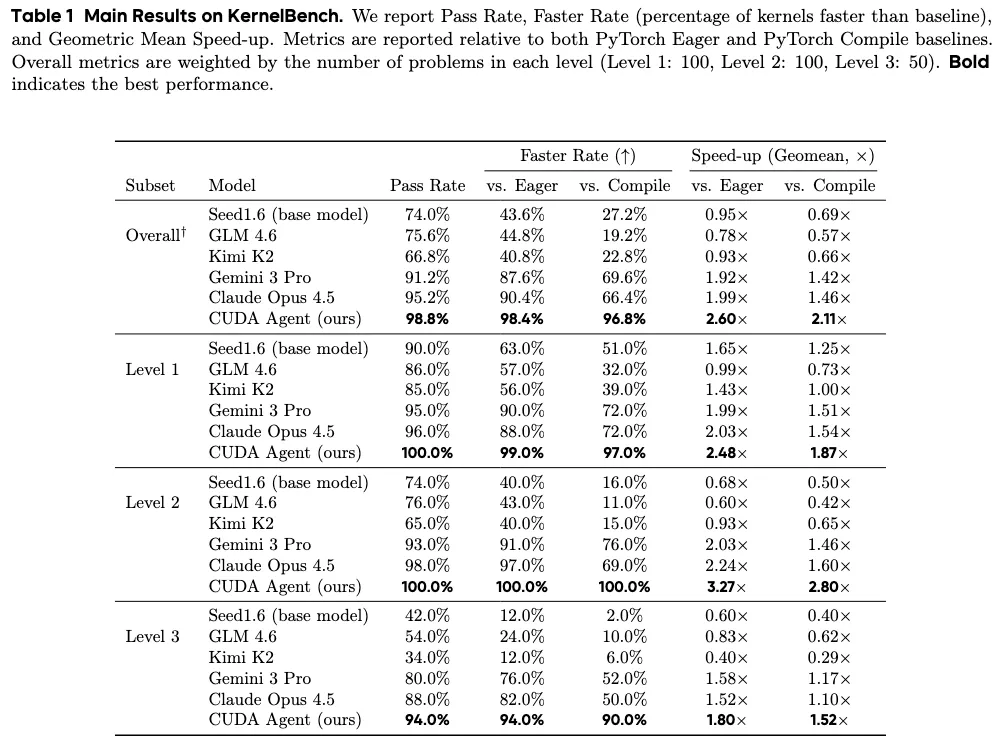
CUDA Agent posts very strong results on KernelBench. On the overall test, it shows a 96.8% faster rate vs. torch.compile and a 2.11x geomean speed-up.
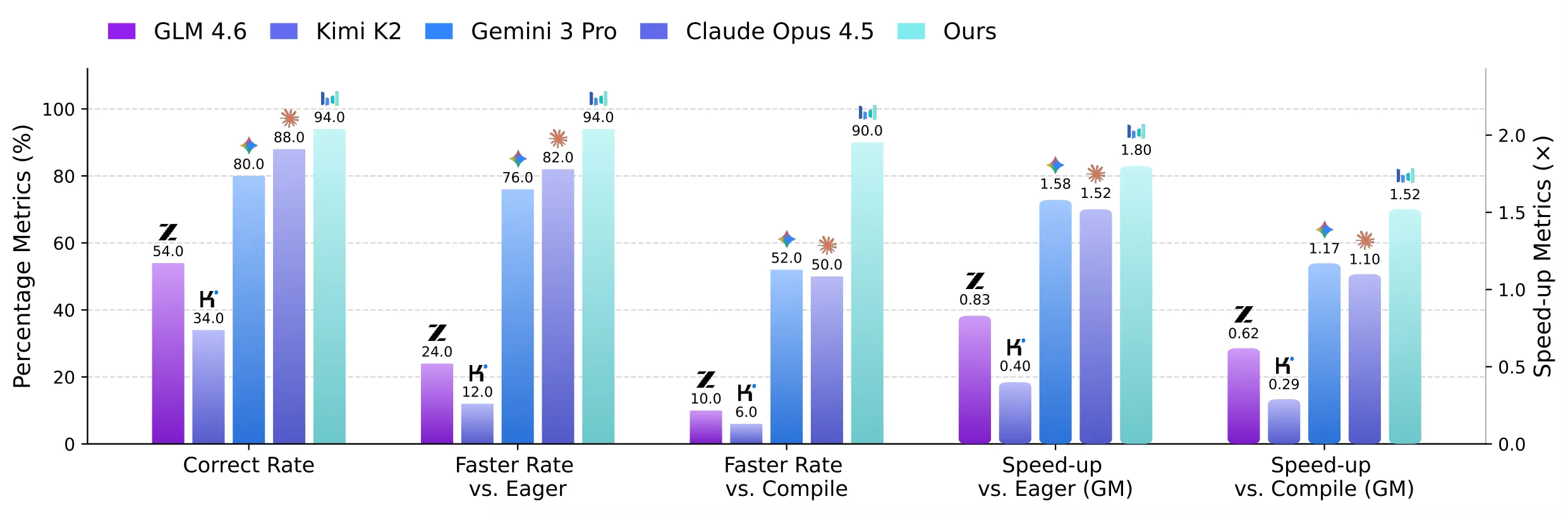
On the hardest Level-3 set, it still pushes a 90% faster rate vs. torch.compile and a 1.52x geomean speed-up. This gap is large when compared to strong proprietary models reported by the authors.
How Supercharging GPU Performance: How CUDA Agent Automates High-Speed Kernel Generation with RL Works
- Start from a PyTorch baseline and measure it.
- Write CUDA kernels and C++ bindings, then compile in a GPU sandbox.
- Run strict correctness checks and profile speed. Repeat until the kernel is both correct and at least 5% faster than torch.compile.
The reward system gives points for milestones like passing checks and beating speed targets. Anti-cheat rules block shortcuts, so gains reflect real kernel quality.
The Technology Behind It
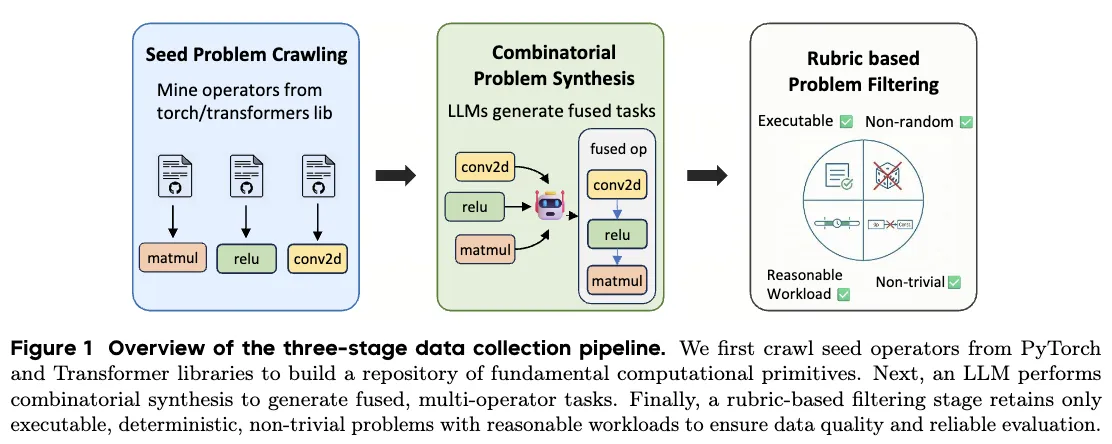
Data Synthesis at Scale
Training tasks come from a three-step process: collect seed ops, compose them into fused tasks, and filter by strict rules. Only tasks that run well in eager and compile modes, are deterministic, and fall in a fair time window make the cut.
Agent Environment and Rewards
The agent follows a ReAct-style loop with coding tools and a CUDA skill spec (SKILL.md). It compiles, debugs, and profiles, while reward controls prevent bad shortcuts like constant outputs or hidden fallbacks.
Stable Long-Context Training
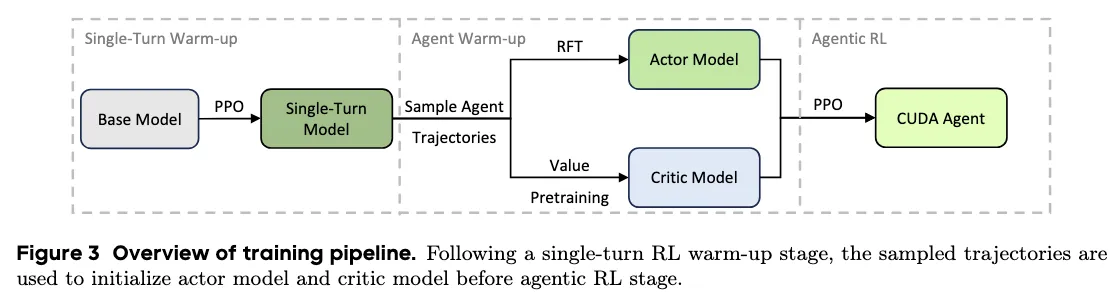
Training uses stages for stability: a single-turn PPO warm-up, Rejection Fine-Tuning (RFT) for the actor, and value pretraining for the critic. This keeps learning steady even with long contexts and many turns.
Who Is Behind Supercharging GPU Performance: How CUDA Agent Automates High-Speed Kernel Generation with RL
CUDA Agent is a joint effort from researchers working on high-performance deep learning. The project site shares news, results, and links to data and code.

Installation & Setup (agent_workdir)
The repository includes a ready-to-use agent workspace called agent_workdir. It shows the full loop: write kernels, compile, verify, profile, and iterate.
Key files inside agent_workdir:
- SKILL.md: workflow constraints and optimization rules for agent execution
- model.py: original PyTorch baseline model
- model_new.py: optimized model using the custom CUDA extension
- binding.cpp / binding_registry.h: shared Python binding registration infrastructure
- kernels/: custom CUDA/C++ kernels and their bindings
- utils/compile.py + utils/compile.sh: extension build scripts
- utils/verification.py: correctness validation script
- utils/profiling.py: performance comparison against baseline and torch.compile
Common commands (run inside agent_workdir):
bash utils/compile.sh
python3 -m utils.verification
python3 -m utils.profiling
Step-by-step guide:
- Open a terminal and switch to agent_workdir.
- Run the compile script to build the CUDA extension.
- Verify correctness.
- Profile speed against the baseline and torch.compile.
- Edit kernels and repeat to chase more speed.
Supercharging GPU Performance: How CUDA Agent Automates High-Speed Kernel Generation with RL FAQ
What is a CUDA kernel?
A CUDA kernel is a small program that runs on the GPU. It handles the heavy math that speeds up deep learning.
What does “faster rate vs. torch.compile” mean?
It is the share of tasks where the agent’s kernel runs faster than torch.compile. Higher is better, since it shows more wins across many tasks.
What is CUDA-Agent-Ops-6K?
It is a training dataset with 6,000 tasks. Each task comes from real PyTorch ops and passes strict rules to keep the data clean and useful for RL.
Do I need to change my whole model to try this?
No. The agent_workdir shows how to add a custom extension to speed up just the slow parts. You can keep the rest of your PyTorch code as is.
How does the project prevent fake speed-ups?
It blocks bad patterns like constant outputs and hidden fallbacks. It uses protected scripts and multiple inputs to make sure the gains are real.
Image source: Supercharging GPU Performance: How CUDA Agent Automates High-Speed Kernel Generation with RL