Dress Any Way: The Future of Arbitrary-Subject Clothing Generation with AnyDressing
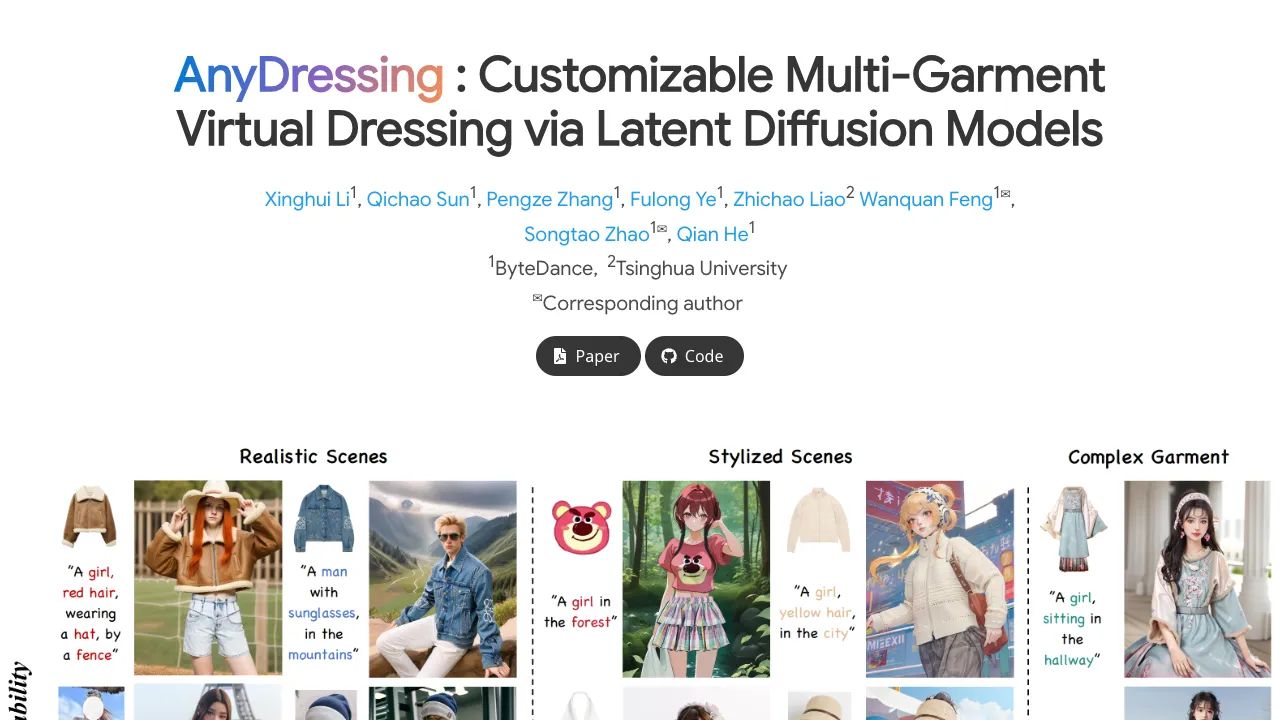
What is Dress Any Way: The Future of Arbitrary-Subject Clothing Generation with AnyDressing
AnyDressing is a research project that lets you dress any person or character in many different clothes at the same time. You can guide it with short text prompts and with pictures of target garments, and it will keep small fabric details like logos, prints, and textures.

The team behind AnyDressing focuses on “multi-garment virtual dressing.” In short, it means you can mix shirts, pants, jackets, shoes, and more, all in one shot, while the body and pose still look right.
Dress Any Way: The Future of Arbitrary-Subject Clothing Generation with AnyDressing Overview
Here is a quick summary of the project.
| Item | Details |
|---|---|
| Project Name | AnyDressing: Customizable Multi-Garment Virtual Dressing via Latent Diffusion Models |
| Type | Research method and soon-to-be released inference code |
| Purpose | Dress any subject with any mix of garments using prompts and garment images |
| Inputs | Text prompts, multiple garment images (N garments), optional control add-ons |
| Outputs | A new image of the subject wearing the chosen garments |
| Core Parts | GarmentsNet, DressingNet |
| Key Modules | Garment-Specific Feature Extractor (GFE), Dressing-Attention (DA), Instance-Level Garment Localization Learning, Garment-Enhanced Texture Learning (GTL) |
| Works With | Community tools like ControlNet, LoRA, and FaceID |
| Status | Paper accepted to CVPR 2025; inference code coming soon |
| Project Page | https://crayon-shinchan.github.io/AnyDressing/ |
| Paper | arXiv: 2412.04146 |
| Best For | Fashion mockups, creator content, ads, cosplay looks, avatar outfits, and research |

For a friendly look at big tech in AI and creative tools, see our Bytedance overview.
Dress Any Way: The Future of Arbitrary-Subject Clothing Generation with AnyDressing Key Features
-
Dress many garments at once. Pick several items and get a single, clean outfit.
-
Clear textures and prints. Small details like stripes, lace, or logos stay sharp.
-
Smart placement. Each garment goes to the right region on the body.
-
Strong text control. Short prompts guide color, style, or vibe without losing garment identity.
-
Works across many scenes. Indoor, outdoor, simple, or stylized looks are supported.
-
Add-on friendly. It can plug into popular tools like ControlNet, LoRA, and FaceID to add pose or identity control.

Dress Any Way: The Future of Arbitrary-Subject Clothing Generation with AnyDressing Use Cases
-
Online stores can show how a shirt, jacket, and skirt look together on a model.
-
Creators can build character outfits for comics, games, or shorts in minutes.
-
Ads and social posts can test several styles very fast, without a photo shoot.
-
Cosplay and fan art makers can swap in exact pieces and keep fabric patterns.
-
Avatar and VTuber teams can preview many styles before rigging or filming.
-
Research teams can study multi-item control for image generation with clear metrics.
For more guides, tools, and updates, visit our home page.
Performance & Showcases
Below is a sample highlight shared by the authors.
Showcase 1 — Customized Characters This clip shows “Customized Characters.” It presents people or stylized subjects wearing chosen garments while keeping textures and prompt intent.

How It Works: The Simple Version
- Step 1: Feed in N garment images and a short text prompt. You can also add control tools if you need pose or identity guidance.
- Step 2: GarmentsNet reads each garment in parallel using a Garment-Specific Feature Extractor. This helps the model keep the clothes apart and avoid mix‑ups.
- Step 3: DressingNet places each garment in the right body area with a special attention step and a region learning trick. A texture booster then sharpens fine details.
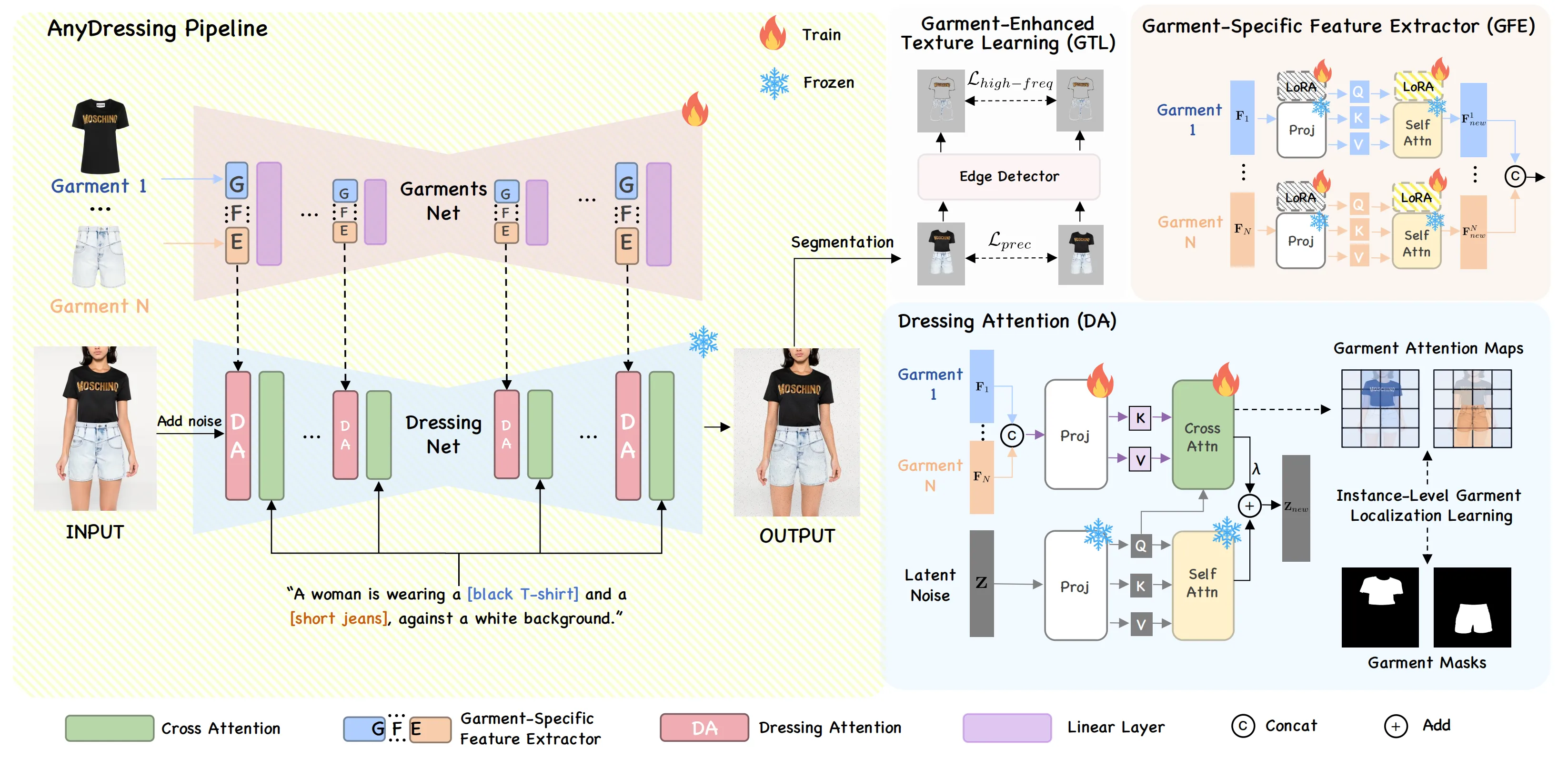
The Technology Behind It (Plain English)
-
Two-part design. One part “reads” garment textures; the other part “dresses” the subject.
-
Parallel garment reading. Each item gets its own track, so shirt details do not bleed into pants or shoes.
-
Region-aware dressing. The system learns to map each garment to the right place on the person and keep prompt meaning.
-
Texture boost. A final pass improves fabric details so prints and knits look clean.
-
Add-on ready. It can work with common plugins like ControlNet, LoRA, and FaceID to guide pose, style, or identity as needed.

Installation & Setup (Getting Started)
-
Code status: The team shared that they are cleaning the code and will release inference code soon.
-
What you can do today:
-
Read the paper on arXiv and the project page to understand inputs and outputs.
-
Prepare a small set of garment images and prompts you want to try once code is out.
-
Watch the GitHub repo for updates and star it to get notified.
-
When the team publishes the inference code, follow their exact steps there. Since no install commands are public yet, please do not rely on unofficial forks.
Tips for Best Results
- Use clear, well-lit garment photos. Front-facing shots with minimal folds work best.
- Keep prompts short and clear. For example: “red floral blouse, black leather jacket, light blue jeans.”
- If you plan to use ControlNet, LoRA, or FaceID, set a goal first. For example, “keep the same person’s face” or “match this pose.”
Roadmap & What’s Next
- 2024/12/06: Paper released to the public.
- 2025/02/27: Accepted by CVPR 2025.
- Next: Inference code release. Expect setup steps and example scripts on the repo.
To learn more about our team and editorial standards, visit our about page.
FAQ
What makes AnyDressing special?
AnyDressing can dress a subject with many different garments at the same time. It keeps small fabric details and follows your text prompt closely. It also works with tools like ControlNet, LoRA, and FaceID.
Can I use AnyDressing today?
The paper and project page are public, but the code is not yet released. The team says inference code is coming soon. You can follow the repo for updates.
Do I need prompts and garment images?
Yes. Short text prompts guide style or color, and garment images bring the exact textures. The model then builds a final image with the chosen pieces.
Does it keep the person’s identity?
If you use tools like FaceID or similar add‑ons, you can guide identity better. The base method focuses on garments and regions. With the right add‑on, you can keep the same face across shots.
What kind of scenes work?
The method is made to work across many settings, from simple studio shots to stylized scenes. Good lighting and clear garments help.
Who is this for?
It is great for fashion teams, creators, ad studios, avatar makers, and research groups. Anyone who needs multi‑item outfit images can benefit.
Image source: Dress Any Way: The Future of Arbitrary-Subject Clothing Generation with AnyDressing